
ランダムフォレストとは?仕組みから活用事例・Python実装まで完全ガイド
この記事でわかること
- ランダムフォレストとは?基本概念と特徴
- ランダムフォレストの仕組みとPythonでの実装方法
- ランダムフォレストのメリット・デメリットと活用事例

「精度の高い予測モデルを使いたいけど、専門的すぎて難しそう…」そう感じたことはありませんか?
本記事では、人気の機械学習アルゴリズム「ランダムフォレスト」について、仕組み・実装方法・活用事例までをわかりやすく解説します。
初心者でも実務に応用できる知識が身につく、学び直しにも最適な完全ガイドです。
※参考記事「機械学習とディープラーニングの違い5選|目的別に最適技術がわかる選び方ガイド」

目次
ランダムフォレストとは|仕組みと初心者が押さえたい基本

ランダムフォレストは、複数の決定木を組み合わせることで高い予測精度を実現する機械学習アルゴリズムです。
名前の通り「ランダム(無作為)な森」として、多数の決定木が集まって強力な予測モデルを形成します。
分類(カテゴリ予測)と回帰(数値予測)の両方に対応できる汎用性の高さから、データサイエンスの現場で広く活用されています。
決定木とアンサンブル学習を組み合わせた手法
決定木は、データの特徴に基づいて「Yes/No」の二択を繰り返し、最終的な予測を行う直感的なアルゴリズムです。
例えば「気温は25度以上か?」「湿度は60%以上か?」といった質問を順に行い、結果として「傘が必要か不要か」を判断していきます。
この階層的な構造が木の枝のように見えることから「決定木」と呼ばれています。
ランダムフォレストはこの決定木を基本単位として、「アンサンブル学習」という手法を採用しています。
アンサンブル学習とは、複数の学習モデル(弱学習器)を組み合わせることで、より精度の高いモデル(強学習器)を構築する手法です。
具体的には「バギング(Bagging: Bootstrap Aggregating)」という手法を用いて、元のデータからランダムに復元抽出したサブセットを作り、それぞれで独立した決定木を学習させます。
この過程で各決定木は異なるデータで学習するため、多様性が確保され、全体としての予測精度が向上するのです。
ランダムサンプリングと特徴量選択の重要性
ランダムフォレストでは2つの「ランダム性」が導入されており、これが名前の由来となっています。
1つ目は「データのランダムサンプリング」です。
元のデータセットから、ランダムに復元抽出(同じデータが複数回選ばれることを許容)することにより、各決定木は少しずつ異なるデータセットで学習します。
これによって、一部のデータに過度に適合してしまう過学習のリスクを軽減しています。
2つ目は「特徴量のランダム選択」です。
各決定木の分岐点(ノード)では、全ての特徴量(説明変数)からランダムに選ばれた一部の特徴量のみを使用して最適な分割を決定します。
例えば10個の特徴量がある場合、各ノードでは3〜4個程度の特徴量だけをランダムに選んで分岐の判断をするのです。
これにより、特定の強い特徴量に全ての決定木が依存することを防ぎ、モデルの多様性を確保しています。
この2つのランダム性によって、個々の決定木は互いに異なる特性を持ち、多様な観点からの「意見」を持つようになります。
このバラエティに富んだ予測結果を集約することで、ランダムフォレスト全体としての予測精度と汎用性が高まるのです。
多数決・平均による高精度な予測の仕組み
ランダムフォレストが最終的な予測を行う際は、全ての決定木の予測結果を統合する「集約」のステップが重要になります。
分類問題と回帰問題では、この集約方法が異なります。
分類問題(カテゴリの予測)では、「多数決」が採用されます。
例えば「このメールはスパムか否か」という二択の問題で、100本の決定木のうち65本が「スパム」と予測し35本が「通常メール」と予測した場合、最終的にはより多くの「票」を獲得した「スパム」が予測結果となります。
ランダムフォレストでは単にクラス予測だけでなく、各クラスの確率も算出できるため「65%の確率でスパム」といった形で結果を表現することも可能です。
一方、回帰問題(数値の予測)では、各決定木の予測値の「平均」を取ります。
例えば「明日の気温予測」というタスクで、100本の決定木がそれぞれ少しずつ異なる温度を予測した場合、それらの平均値が最終予測となります。
この平均化によって外れ値の影響が緩和され、より安定した予測結果が得られます。
この多数決や平均による集約プロセスにより、ランダムフォレストは個々の決定木の誤差を相殺し、全体としての予測精度を向上させています。
各決定木が異なるデータと特徴量で学習しているため、それぞれの誤りが独立している可能性が高く、集約によって「群衆の知恵」が生まれるのです。
この特性により、ランダムフォレストは過学習に強く、安定した予測性能を発揮します。
ランダム フォレストの3つの主要な特長と利点

ランダムフォレストが機械学習の現場で広く採用されている理由は、いくつかの優れた特性にあります。
単に予測精度が高いだけでなく、実務上の使いやすさや応用の幅広さなど、様々なメリットを兼ね備えています。
ここでは、ランダムフォレストの3つの主要な特長と利点について詳しく見ていきましょう。
高い予測精度と過学習への強いロバスト性
ランダムフォレストの最大の強みは、高い予測精度を維持しながらも過学習に強いという特性です。
一般的に機械学習モデルは、学習データに過度に適合してしまう「過学習(オーバーフィッティング)」の問題に悩まされます。
過学習が起きると、未知のデータに対する予測性能が著しく低下してしまうのです。
ランダムフォレストでは、複数の決定木がそれぞれ異なるデータサブセットと特徴量で学習するため、個々のモデルのバイアスが相互に打ち消し合います。
ある決定木が特定のパターンに過剰適合していても、他の決定木がそれとは異なるパターンに反応するため、全体としては過学習のリスクが軽減されるのです。
これは「アンサンブル効果」と呼ばれ、単一モデルよりも安定した予測性能をもたらします。
実際の比較実験でも、ランダムフォレストは単一の決定木や他の多くの機械学習アルゴリズムよりも高い精度を示すことが多く、特に中規模から大規模のデータセットで優れた性能を発揮します。
特徴量の重要度評価と解釈可能性
ランダムフォレストは「ブラックボックス」と呼ばれる複雑なモデルの中では比較的解釈しやすいという特長があります。
特に、各特徴量(変数)がモデルの予測にどれくらい貢献しているかを数値化する「特徴量重要度(Feature Importance)」の評価が可能です。
特徴量重要度は、各決定木の分岐で使用された特徴量と、その分岐によってどれだけ予測精度が向上したかを集計することで算出されます。
例えば「年齢」という特徴量が多くの決定木で重要な分岐点として使われていれば、その重要度は高くなります。
この情報は、ビジネス上の意思決定や科学的知見の獲得に直接役立ちます。
「なぜその予測結果になったのか」という説明が求められるビジネスや医療などの分野では、この解釈可能性は非常に重要です。
ディープラーニングなどの他の高性能モデルと比較しても、ランダムフォレストはこの点で優位性を持っています。
様々なデータタイプへの適応力
ランダムフォレストは様々なタイプのデータに対して柔軟に対応できる汎用性の高さも大きな魅力です。
数値データはもちろん、カテゴリカルデータ(性別や職業など)も適切に処理できます。
また、特徴量間のスケールの違い(例:年齢とドル単位の収入)に影響されにくいため、正規化や標準化などの前処理が最小限で済むことも実務上の大きなメリットです。
さらに、ランダムフォレストは欠損値や外れ値にも比較的頑健で、データクリーニングの負担が軽減されます。
高次元データ(特徴量が多い状況)でも性能が安定していることから、多様な分野への応用が可能です。
実装面でも、主要なプログラミング言語やデータサイエンスライブラリでサポートされており、比較的少ないコード量で実装できます。
ハイパーパラメータの調整も他のアルゴリズムに比べて直感的で、初期設定でもある程度の性能が得られることが多く、機械学習初心者にも扱いやすいモデルとなっています。
ランダム フォレストをPythonで実装する方法

Pythonは機械学習の実装において最も人気の高いプログラミング言語の一つであり、ランダムフォレストを簡単に実装できる環境が整っています。
特に「Scikit-learn(サイキット・ラーン)」というライブラリを使うことで、複雑な数学的背景を深く理解していなくても、効果的なランダムフォレストモデルを構築できます。
ここでは、実践的なコード例とともに、基本的な実装から高度なチューニングまでを解説します。
Scikit-learnによる基本的な実装ステップ
Scikit-learnを使ったランダムフォレストの実装は非常に直感的です。
まずは必要なライブラリをインポートし、基本的な分類モデルを構築する例を見てみましょう。
# 必要なライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# サンプルデータの読み込み(CSVファイルの場合)
data = pd.read_csv(‘your_data.csv’)
# 特徴量とターゲット変数の分離
X = data.drop(‘target_column’, axis=1) # 特徴量
y = data[‘target_column’] # ターゲット変数
# データを学習用とテスト用に分割(8:2の比率)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ランダムフォレストモデルの構築と学習
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# テストデータでの予測
y_pred = rf_model.predict(X_test)
# モデルの精度評価
accuracy = accuracy_score(y_test, y_pred)
print(f’モデルの精度: {accuracy:.4f}’)
回帰問題(数値予測)の場合は、RandomForestClassifierの代わりにRandomForestRegressorを使用します。
評価指標も分類とは異なり、平均二乗誤差(MSE)や決定係数(R²)などが一般的です。
ランダムフォレストの大きな利点の一つに、特徴量の重要度を容易に取得できる点があります。
以下のコードで特徴量の重要度を可視化できます。
# 特徴量の重要度の確認
feature_importances = pd.DataFrame(
{‘feature’: X_train.columns, ‘importance’: rf_model.feature_importances_}
)
feature_importances = feature_importances.sort_values(‘importance’, ascending=False)
# 可視化(matplotlibを使用)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.barh(feature_importances[‘feature’], feature_importances[‘importance’])
plt.xlabel(‘重要度’)
plt.title(‘特徴量の重要度’)
plt.tight_layout()
plt.show()
効果的なハイパーパラメータチューニング
ランダムフォレストには様々なハイパーパラメータがあり、これらを適切に調整することでモデルの性能を大きく向上させることができます。
主要なパラメータには以下のようなものがあります。
・n_estimators:決定木の数(多いほど精度が上がる傾向がありますが、計算コストも増加)
・max_depth:各決定木の最大深さ(深すぎると過学習の原因に)
・min_samples_split:ノードを分割するために必要な最小サンプル数
・min_samples_leaf:葉ノードに必要な最小サンプル数 ・max_features:各分割で考慮する特徴量の数
これらのパラメータを手動で調整するのは時間がかかるため、Scikit-learnのGridSearchCVやRandomizedSearchCVを使った自動チューニングが便利です。
from sklearn.model_selection import GridSearchCV
# 探索するパラメータの範囲を定義
param_grid = {
‘n_estimators’: [100, 200, 300],
‘max_depth’: [None, 10, 20, 30],
‘min_samples_split’: [2, 5, 10],
‘min_samples_leaf’: [1, 2, 4]
}
# グリッドサーチの設定(交差検証も同時に行う)
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5, # 5分割交差検証
n_jobs=-1, # 使用可能なすべてのCPUコアを使用
verbose=1
)
# グリッドサーチを実行
grid_search.fit(X_train, y_train)
# 最適なパラメータと精度の確認
print(f’最適なパラメータ: {grid_search.best_params_}’)
print(f’最高精度: {grid_search.best_score_:.4f}’)
# 最適化されたモデルを取得
best_rf_model = grid_search.best_estimator_
パフォーマンス評価と最適化テクニック
ランダムフォレストモデルの評価では、単純な精度だけでなく、様々な指標を確認することが重要です。
特に分類問題では、適合率(Precision)、再現率(Recall)、F1スコア、ROC-AUCなどが有用です。
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score
# 様々な評価指標の確認
y_pred_proba = best_rf_model.predict_proba(X_test)[:, 1] # 確率予測
print(confusion_matrix(y_test, best_rf_model.predict(X_test)))
print(classification_report(y_test, best_rf_model.predict(X_test)))X
print(f’ROC-AUC: {roc_auc_score(y_test, y_pred_proba):.4f}’)
ランダムフォレストの性能を向上させるための最適化テクニックには、以下のようなものがあります。
・特徴量エンジニアリング:新しい特徴量の作成や不要な特徴量の削除
・特徴量の選択:重要度の低い特徴量を除外して計算効率を向上
・アンサンブル手法の組み合わせ:ランダムフォレストと他のモデルを組み合わせる
・学習データのバランス調整:クラス不均衡問題への対処
最後に、構築したモデルを保存して再利用できます。
import joblib
# モデルの保存
joblib.dump(best_rf_model, ‘random_forest_model.joblib’)
# 後でモデルを読み込む場合
loaded_model = joblib.load(‘random_forest_model.joblib’)
これらの基本的な実装手順とテクニックを押さえておけば、実務でのランダムフォレスト活用の第一歩を踏み出すことができるでしょう。
ランダム フォレストの7つの実践的活用事例
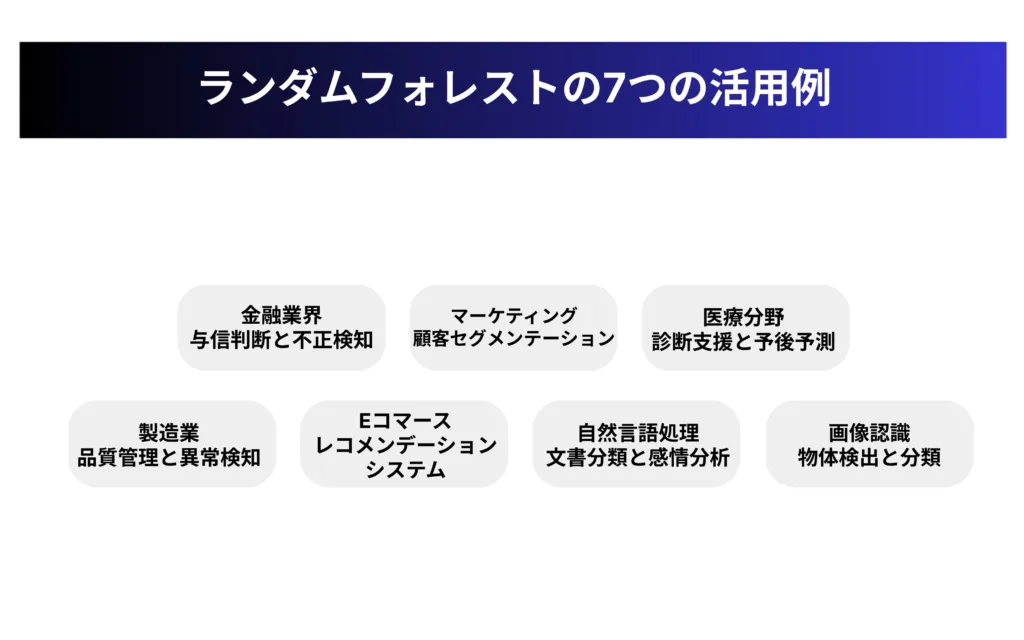
ランダムフォレストは理論だけでなく、実際のビジネスや研究現場で幅広く活用されています。
その高い予測精度と汎用性から、様々な業界で重要な意思決定プロセスを支えるツールとなっています。
ここでは、ランダムフォレストがどのように実務で活用されているのか、7つの具体的な事例を紹介します。
金融業界での与信判断と不正検知
金融機関ではリスク管理が最重要課題の一つであり、ランダムフォレストはこの分野で強力なツールとなっています。
与信判断(クレジットスコアリング)では、申込者の属性、財務状況、取引履歴などから、返済能力や債務不履行リスクを評価します。
ランダムフォレストの特徴量重要度機能により、どの要素がリスク評価に最も影響しているかを特定することも可能です。
また、不正検知の分野でも高い成果を上げています。
クレジットカード取引の異常パターンを検出し、不正利用を早期に発見することで、金融機関と顧客の損失を最小限に抑えることができます。
実際に大手クレジットカード会社では、ランダムフォレストを活用した不正検知システムによって、誤検知率を低く保ちながら不正検出率を向上させることに成功しています。
マーケティングにおける顧客セグメンテーション
マーケティング分野では、顧客データを分析して効果的な戦略を立てることが競争優位性につながります。
ランダムフォレストは、購買履歴、人口統計学的特性、行動データなどを基に顧客をセグメント化し、類似した特性を持つグループを特定するのに役立ちます。
例えば、ある小売チェーンでは、ランダムフォレストを使って「1回の来店で高額購入する傾向がある顧客」のプロファイルを作成し、効率的なターゲティングを実現しました。
これにより、マーケティングキャンペーンの費用対効果が大幅に向上し、顧客一人当たりの平均購買額が20%増加した事例も報告されています。
さらに、将来的な顧客の離反予測にも活用でき、事前に効果的な対策を講じることができます。
医療分野での診断支援と予後予測
医療分野では、患者データからの疾病予測や診断支援、治療効果の予測などにランダムフォレストが活用されています。
例えば、血液検査値、バイタルサイン、画像診断結果などの医療データを組み合わせて、特定の疾患のリスク評価を行うことができます。
具体的な応用例としては、糖尿病の早期発見や心筋梗塞のリスク評価などがあります。
また、がん患者の治療反応性や予後予測にも使われており、医師の診断を補助する意思決定支援ツールとしての役割を果たしています。
ランダムフォレストの重要な特徴は、なぜその予測結果になったのかを特徴量重要度によって説明できる点であり、医療のような説明責任が重要な分野で特に価値が高いとされています。
製造業における品質管理と異常検知
製造業では、生産ラインから得られるセンサーデータやプロセスパラメータを分析して、製品品質の予測や異常検知を行うためにランダムフォレストが使われています。
複数のセンサーからのデータを統合分析することで、製品の不良発生を事前に予測したり、異常が発生した際の根本原因を特定したりすることができます。
例えば、半導体製造プロセスでは、数百のパラメータから最終製品の品質に影響を与える重要因子を特定し、不良率を低減するための施策に役立てています。
また、設備の予知保全にも活用されており、機械の故障を事前に予測することで、計画的なメンテナンスを実施し、ダウンタイムを最小化することに成功している企業も多くあります。
Eコマースのレコメンデーションシステム
Eコマースサイトでは、顧客の購買体験を向上させるためのパーソナライズされた商品推薦にランダムフォレストが活用されています。
顧客の過去の閲覧履歴、購買パターン、デモグラフィックデータなどを基に、興味を持ちそうな商品を予測し、レコメンデーションとして提示します。
大手ECサイトでは、ランダムフォレストを用いたレコメンデーションエンジンの導入により、クリック率や転換率(コンバージョンレート)の向上を実現しています。
特に多様な商品カテゴリを扱うECサイトでは、ランダムフォレストの多様な特徴を扱う能力が強みとなり、ユーザー満足度と売上の向上に貢献しています。
また、「この商品を購入した人はこんな商品も購入しています」のような関連商品推薦にも効果を発揮しています。
自然言語処理での文書分類と感情分析
テキストデータの分析においても、ランダムフォレストは重要な役割を果たしています。
テキストから抽出した特徴量(単語の出現頻度、TF-IDFなど)を使用して、文書の分類やセンチメント(感情)分析を行います。
例えば、顧客レビューやSNS投稿から肯定的/否定的な意見を自動的に検出し、ブランドや製品に対する市場の反応をリアルタイムで把握することができます。
メディア企業やマーケティングリサーチ会社では、大量のニュース記事やSNSデータを自動分類し、トレンド分析やブランド評判の追跡に活用しています。
また、カスタマーサポートの分野では、問い合わせ内容の自動分類によって適切な担当者への振り分けを効率化し、対応時間の短縮とサービス品質の向上を実現しています。
画像認識における物体検出と分類
画像認識の分野でも、ランダムフォレストは物体検出や分類タスクに応用されています。
特にディープラーニングが普及する前は、HOG(Histogram of Oriented Gradients)やSIFT(Scale-Invariant Feature Transform)などの特徴量と組み合わせて、物体認識や顔検出などに幅広く使われていました。
具体的な活用例としては、関西デジタルソフト株式会社が開発した「毒キノコ検知システム」が挙げられます。このシステムでは、キノコの傘の形状や色、表面の特徴、香りなどの特徴量から、食べられるキノコかどうかを自動判断しています。
また、医療画像診断の補助ツールとしても利用されており、X線画像やMRI画像から異常を検出する際の判断支援に役立てられています。
工場の検査ラインでの製品不良検出など、産業用途での画像検査システムにも組み込まれています。
ランダムフォレスト導入時の注意点:精度を引き出す実践アドバイス
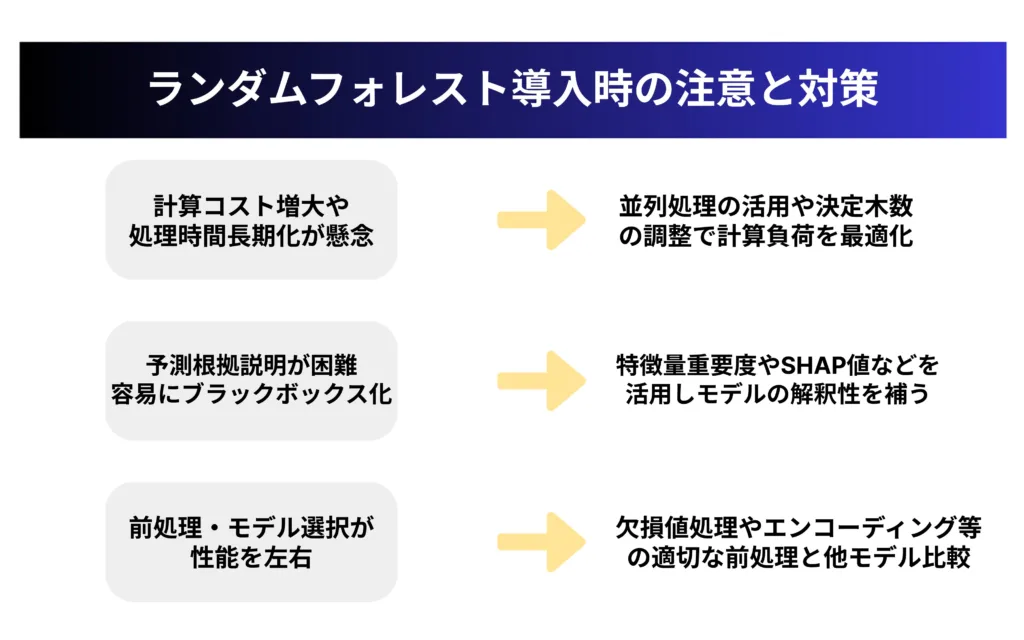
ランダムフォレストは多くの利点を持つ強力なアルゴリズムですが、実務に導入する際にはいくつかの課題や注意点があります。
これらの問題を事前に理解し、適切な対策を講じることで、ランダムフォレストの性能を最大限に引き出し、プロジェクトを成功に導くことができます。
ここでは、実践的な観点から主要な3つの課題と、それらに対する効果的な対策を解説します。
計算リソースと処理時間の最適化
ランダムフォレストは多数の決定木を構築・評価するため、データセットが大きくなると計算コストが増大します。
特に数百万レコード以上のビッグデータや、数百以上の特徴量を持つ高次元データを扱う場合、メモリ不足や処理時間の長期化が問題になることがあります。
この課題に対処するためには、以下のような最適化戦略が効果的です。
・並列処理の活用:ランダムフォレストは本質的に並列処理に適したアルゴリズムです。
Scikit-learnではn_jobsパラメータを設定することで、複数のCPUコアを利用した並列計算が可能です。
・決定木の数の調整:多くの場合、100〜500本程度の決定木で十分な精度が得られるため、必要以上に多くの決定木を生成しないようにします。
精度と計算コストのトレードオフをグラフ化して最適点を見つけるのが良いでしょう。
・サンプリングの活用:非常に大きなデータセットでは、データの一部をサンプリングして学習に使用することで、計算コストを大幅に削減できる場合があります。
・インクリメンタル学習:新しいデータが継続的に追加される場合は、モデルを最初から再学習するのではなく、増分学習を検討します。
これらの対策により、大規模データにおいても実用的な時間内でランダムフォレストの学習と予測を行うことが可能になります。
解釈性の向上とブラックボックス問題の対処法
ランダムフォレストは単一の決定木に比べると「ブラックボックス」の側面が強く、「なぜこの予測結果になったのか」を説明することが難しい場合があります。
特に金融や医療など、意思決定の透明性が重要な分野では、この解釈性の低さが導入の障壁となることがあります。
この解釈性の課題に対処するには、以下のようなアプローチが有効です。
・特徴量重要度の活用:ランダムフォレストが提供する特徴量重要度(Feature Importance)を分析し、どの変数が予測に大きく寄与しているかを示します。
・部分依存プロット(PDP):特定の変数が予測にどのように影響しているかを視覚的に表現する手法です。
・SHAP(SHapley Additive exPlanations)値:ゲーム理論に基づき、各特徴量の予測への貢献度を詳細に分解して説明できます。
・ローカル解釈可能性:LIME(Local Interpretable Model-agnostic Explanations)などの手法を用いて、個別の予測結果について局所的な説明を提供します。
これらのテクニックを活用することで、複雑なランダムフォレストモデルの挙動をより透明化し、ステークホルダーの理解と信頼を得やすくなります。
データ前処理とモデル選択のベストプラクティス
ランダムフォレストは比較的頑健なアルゴリズムですが、適切なデータ前処理を行うことで、その性能をさらに向上させることができます。
また、問題によっては他のアルゴリズムの方が適している場合もあります。
効果的なデータ前処理とモデル選択のベストプラクティスとしては、以下が挙げられます。
・欠損値の処理:ランダムフォレストは欠損値に対してある程度頑健ですが、事前に適切な補完(平均値、中央値、予測値など)を行うことで、さらに精度を向上させることができます。
・カテゴリカル変数のエンコーディング:カテゴリカル変数は、One-Hotエンコーディングやターゲットエンコーディングなどの方法で数値に変換します。
・スケーリングの判断:ランダムフォレストは変数のスケールに影響されにくいアルゴリズムですが、特徴量の範囲が極端に異なる場合は、正規化や標準化を検討します。
・モデル比較の実施:グラディエントブースティング(XGBoost、LightGBMなど)や深層学習など、他のアルゴリズムとの性能比較を行い、最適なモデルを選択します。
適切なデータ前処理とモデル選択により、ランダムフォレストの性能を最大限に引き出し、より高精度な予測モデルを構築することができます。
まとめ:ランダム フォレストで実現するデータ駆動型意思決定

本記事では、機械学習アルゴリズムのランダムフォレストについて、基本概念から実装方法、実践的な活用事例まで幅広く解説しました。
ランダムフォレストは、その高い予測精度と過学習への耐性、さらには比較的解釈しやすいという特性から、ビジネスにおけるデータ駆動型意思決定の強力なツールとなります。
金融、マーケティング、医療、製造業など様々な分野で活用され、従来の経験や勘に頼る意思決定から、データに基づく客観的な判断へとシフトする原動力となっています。
Pythonを使った実装も比較的容易で、初めての機械学習プロジェクトにも取り組みやすいアルゴリズムといえるでしょう。
計算リソースや解釈性などの課題はありますが、適切な対策を講じることで、これらの限界を克服することが可能です。
ランダムフォレストを起点に機械学習の世界に踏み出し、組織のデータ資産を最大限に活用した意思決定の変革を実現してみてはいかがでしょうか。
【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


