
ローカルLLMとは?5つのメリットと導入ステップをやさしく解説
この記事でわかること
- ローカルLLMとは?定義と注目の理由を解説
- ローカルLLMのメリットと課題
- ローカルLLMの導入方法と活用事例

ChatGPTやClaudeの登場により、企業での生成AI活用が急速に広がっています。
ただ一方で、「クラウドに預けるのはちょっと不安…」「コストや柔軟性に課題がある」と感じている方も多いのではないでしょうか。
そんな中、注目されているのがローカルLLM。
社内ネットワークだけで動かせるAIモデルは、データの安全性やコスト面で大きな魅力があります。
この記事では、ローカルLLMの基本から、モデル選定・環境構築・導入ステップまでをわかりやすく解説します。
自社にフィットしたAI基盤づくりのヒントとして、ぜひ参考にしてください。

目次
ローカルLLMとは?基本概念と用途を解説

近年、AIの活用が進む中で「ローカルLLM」という言葉をよく耳にするようになりました。
クラウドベースのAIサービスが主流の今、なぜローカル環境でLLMを動かす選択肢が注目されているのでしょうか。
ここでは、ローカルLLMの基本から、クラウドLLMとの違い、そして特に効果を発揮する場面までを詳しく解説します。
ローカルLLMの定義と基本的な特徴
ローカルLLM(ローカル大規模言語モデル)とは、クラウド環境ではなく、自社のサーバーやPC上で直接動作させる大規模言語モデルのことです。
インターネット接続を必要とせず、すべてのデータ処理をローカル環境内で完結させる点が最大の特徴です。
主な特徴としては、データが外部に送信されないセキュリティ面での優位性、ネットワーク遅延のない即時応答性、カスタマイズの自由度の高さなどが挙げられます。
実行方法としては、高性能なGPUを活用した高速推論と、CPUのみでの軽量推論(量子化モデルを利用)の2つのアプローチがあります。
Ollama、LM Studio、Text Generation Web UIなどのツールを使って、比較的簡単に環境構築が可能になっています。
クラウドLLMとローカルLLMの違いと選択基準
クラウドLLMとローカルLLMの最も大きな違いは実行環境と管理主体です。
クラウドLLMはサービス提供者のサーバー上で動作し、APIを通じて利用するのに対し、ローカルLLMはユーザー自身の環境で完結します。
選択基準としては、以下のポイントを考慮すると良いでしょう。
セキュリティ要件が厳しく、機密データを扱う場合はローカルLLMが適しています。
一方で、初期投資を抑えたい場合や、GPU数枚でも対応できないような、大規模な生成タスク(数十万語レベルの文書生成など)では、クラウドLLMの強力なバックエンドのほうが安定します。
また、技術的な管理リソースが限られている企業はクラウドサービスを選択し、カスタマイズ性を重視するならローカルLLMを検討すべきです。
インターネット接続が不安定な環境や、低レイテンシが求められるリアルタイムアプリケーションでは、ローカルLLMが優位性を発揮します。
ローカルLLMが特に効果を発揮する業界と事例
ローカルLLMは特定の業界や利用シーンで大きな効果を発揮します。
医療分野では患者の診療データや遺伝情報など機密性の高いデータを外部漏洩のリスクなく処理でき、医療文書の要約や診断支援などに活用されています。
金融業界でも顧客情報や取引データなど高度なセキュリティが求められる環境で、不正検知や投資分析などに応用されています。
製造業では設計図や製品仕様書などの知的財産を保護しながら、技術文書の生成や検索システムの高度化に利用されています。
法律事務所や特許事務所でも、依頼者情報や訴訟関連文書など極めて機密性の高い情報を扱う場面で採用が進んでいます。
また、インターネット接続のない環境(船舶、辺境地、工場など)での業務支援ツールとしても活躍しています。
ローカルLLMの5つの主要メリットを徹底解説

ローカルLLMを導入する最大の魅力は、クラウドベースのAIサービスでは実現できない独自のメリットにあります。
企業がビジネスにAIを取り入れる際、安全性やコスト効率、パフォーマンスなど様々な観点から検討が必要ですが、ローカルLLMはそれらの課題に対する解決策を提供します。
ここでは、導入を検討する際に押さえておくべき5つの主要メリットを詳しく解説します。
データセキュリティとプライバシー保護の強化
ローカルLLMの最大のメリットは、データが自社環境内で完結する点です。
クラウドサービスでは、入力データが外部サーバーに送信されるため、機密情報の漏洩リスクが常に存在します。
一方、ローカルLLMでは、データが外部ネットワークを通過することなく処理されるため、この懸念を根本的に解消できます。
医療情報や顧客データ、企業の知的財産など、高度な機密性が求められる情報を扱う場面では特に有効です。
また、GDPR(EU一般データ保護規則)やHIPAA(米国医療保険の携行性と責任に関する法律)などの厳格なコンプライアンス要件がある業界でも、データがローカル環境内に留まることで規制対応が容易になります。
ネットワーク非依存の安定性と即時応答性
クラウドAIサービスでは、ネットワーク状況に左右される不安定さが課題となります。
特に接続が不安定な環境や通信帯域が限られる状況では、サービス品質が著しく低下する恐れがあります。
ローカルLLMはこの問題を完全に解消し、インターネット接続の有無にかかわらず常に安定したパフォーマンスを発揮します。
また、クラウドサービスで発生する通信遅延(レイテンシ)が存在しないため、レスポンスが格段に向上します。
特にリアルタイム処理が求められる製造現場での異常検知や、医療現場での緊急対応など、即時性が重要なユースケースで大きな差が生まれます。
これにより、ユーザー体験が飛躍的に向上し、業務効率化にも直結します。
API利用料不要による長期的なコスト削減効果
クラウドベースのAIサービスでは、APIコール数やトークン数に応じた従量課金が一般的です。
利用が増えるほどコストが膨らむ仕組みのため、大規模な運用や継続的な利用では予想以上の費用がかかることがあります。
対照的に、ローカルLLMは初期導入コスト(ハードウェア投資・環境構築)はかかるものの、利用量に関わらず追加料金は発生しません。
例えば、一日あたり1,000回のAPIリクエストを行う場合、主要なクラウドLLMサービスでは月額10万円前後のコストがかかるケースもあります。
これが年間で120万円、3年で360万円に達します。一方、ローカルLLMのための初期投資(高性能GPUサーバー等)が300万円だとしても、2〜3年で投資回収が可能となり、長期的には大幅なコスト削減につながります。
業務特化型AIモデルのカスタマイズ自由度
クラウドAIサービスでは、基本的に提供企業が定めた仕様の範囲内でしか利用できません。
一方、ローカルLLMでは、自社の業務やニーズに合わせた細かなチューニングやカスタマイズが可能です。
特に業界特化の専門用語や社内特有の言い回しなどに対応したモデル作りができる点は大きな強みです。
自社の文書データでファインチューニングを行うことで、汎用モデルでは実現できない高精度な応答を得られます。
例えば、製薬会社での研究データ分析や法律事務所での判例検索など、専門性の高い分野ほどカスタマイズの恩恵は大きくなります。
また、特定のタスク(要約・分類・抽出など)に特化させることで、処理速度と精度の両面で最適化が可能です。
インフラ管理とデータ主権の完全なコントロール
ローカルLLMでは、AIシステムの全てのコンポーネントを自社で管理できます。
クラウドベンダーの突然の仕様変更や価格改定、サービス終了などのリスクから解放され、長期的な事業計画を立てやすくなります。
また、自社のITインフラと完全に統合できるため、既存システムとの親和性も高まります。
さらに、データの所有権と管理権(データ主権)を完全に保持できる点も重要なメリットです。
国際情勢の変化やデータローカライゼーション(データの国内保持義務)などの規制強化が進む昨今、データの越境移転に制限がある場合でも、ローカルLLMなら安心して利用できます。
モデルのバージョン管理や更新頻度も自社のペースで行えるため、ビジネスニーズに最適化された環境を維持できます。
ローカルLLM導入時に考慮すべき課題と対策
ローカルLLMは多くのメリットをもたらす一方で、導入にあたっては克服すべきいくつかの課題があります。
事前に課題を把握し、適切な対策を講じることで、スムーズな導入と運用が可能になります。
ここでは主要な3つの課題とその対策について解説します。
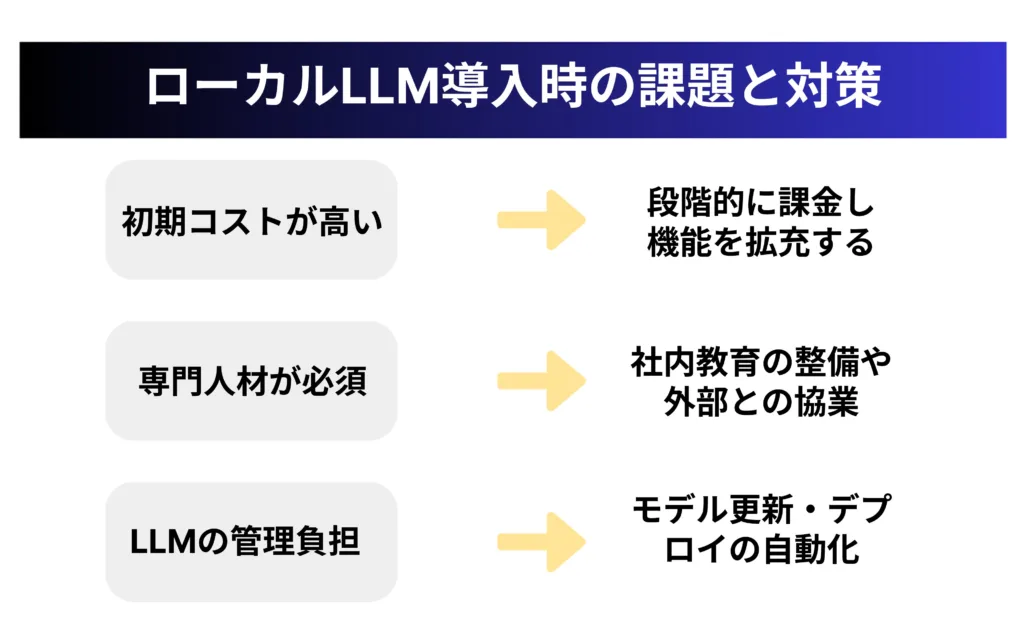
初期導入コストと必要なリソースの計画
ローカルLLM導入の最大の障壁となるのが初期コストの高さです。
高性能なGPUサーバーや大容量ストレージなど、必要なハードウェアの調達には数百万円から数千万円の投資が必要になります。
また、電力消費量の増加や冷却設備の強化など、運用コストも無視できません。
この課題に対しては、段階的な導入アプローチが有効です。
初期段階では小規模なモデル(7B〜13Bパラメータ程度)から始め、効果を確認しながら徐々に拡張していくことで、リスクを抑えつつ投資対効果を検証できます。
また、量子化技術を活用することで、必要なハードウェアスペックを抑える工夫も重要です。
例えば、モデルを量子化(GGUF形式など)することで、GPUメモリ要件を大幅に削減することが可能です。
クラウドとのハイブリッド運用も検討価値があり、特に初期段階ではクラウド環境でテストし、本番環境のみをローカルで運用する方法も選択肢となります。
技術専門知識と人材確保のポイント
ローカルLLMの運用には、機械学習、インフラ管理、セキュリティなどの専門知識を持つ人材が不可欠です。
しかし、これらのスキルを持つ人材の確保は容易ではなく、多くの企業で人材不足が課題となっています。
対策としては、まず社内教育プログラムの整備が挙げられます。
既存のIT人材に対してAI関連のトレーニングを提供し、スキルアップを支援することで、中長期的な人材基盤を構築できます。
短期的には外部パートナーとの協業も有効で、AIコンサルティング企業やMSP(マネージドサービスプロバイダー)との提携により、専門的なサポートを受けながら社内ノウハウを蓄積していくアプローチが考えられます。
また、オープンソースコミュニティへの参加も重要です。
GitHub等でのコミュニティ活動を通じて最新情報を入手し、他組織との知見共有によって技術課題の解決を図ることができます。
モデル更新・管理の効率化手法
ローカルLLMでは、モデルの更新やバージョン管理などを自社で行う必要があり、これらの管理負担が大きな課題となります。
特に、セキュリティパッチの適用や最新技術への対応など、継続的なメンテナンスが求められます。
効率的な管理のためには、まずCI/CDパイプラインの構築が重要です。
モデルの更新やデプロイを自動化することで、手作業によるミスを減らし、運用負荷を軽減できます。
また、コンテナ技術(DockerやKubernetes)の活用により、モデルの配布や環境の一貫性確保が容易になります。
モデルのバージョン管理システムを導入し、各バージョンのパフォーマンスや特性を追跡することも有効です。
さらに、モニタリング体制の確立により、モデルのパフォーマンス低下や異常を早期に検知し、迅速な対応を可能にします。
将来的には、オートスケーリングなどの自動化技術を取り入れることで、負荷に応じた柔軟なリソース調整を実現することも検討すべきでしょう。
おすすめローカルLLMモデルと選定ガイド
ローカルLLMの導入を検討する際、適切なモデルの選択は成功の鍵を握ります。
現在、複数の大手テック企業やAI研究機関がオープンソースモデルを提供しており、それぞれに特徴や強みがあります。
ここでは、特に注目すべき主要モデルの特性と、自社の用途に最適なモデルを選定するためのポイントを解説します。
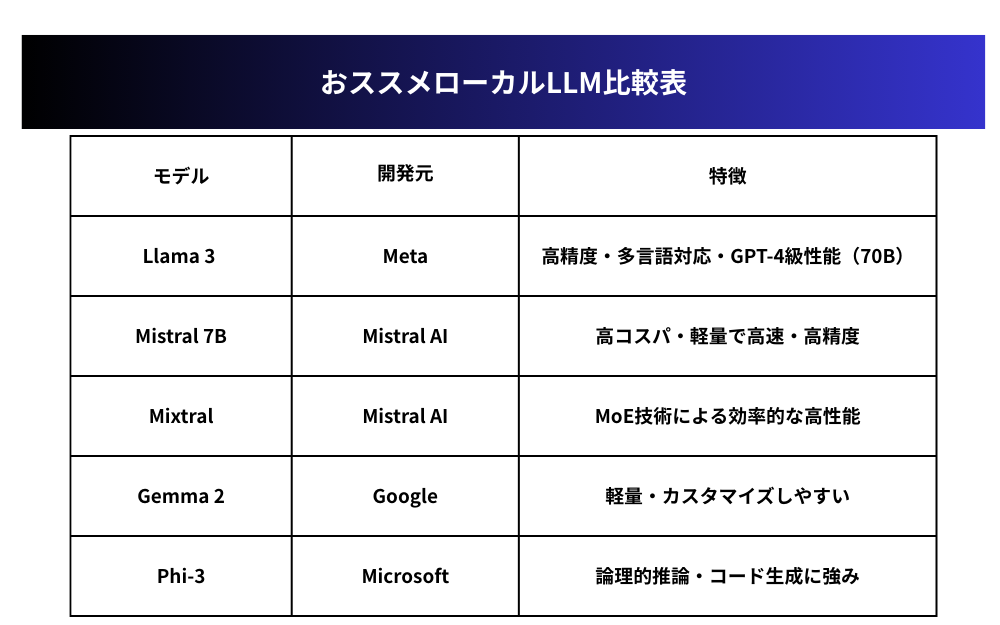
Meta社のLlama 3とその活用法
Meta社が開発したLlama 3は、オープンソースLLMの中でも最も注目を集めるモデルの一つです。
8B(80億)と70B(700億)パラメータの2つのバリエーションが提供され、商用利用も許可されています。
特に70Bモデルは、一部のベンチマークではGPT-4に迫る性能を発揮しており、高品質な生成能力と幅広い知識を持つのが特徴です。
Llama 3の活用法としては、コーディング支援や社内ナレッジ管理、カスタマーサポート自動化などが代表的です。
特に日本語を含む多言語対応が強化されたため、グローバル展開する企業にも適しています。
必要リソースについては、8Bモデルは16GB程度のGPUメモリで動作可能ですが、70Bモデルはフルスペックで80GB以上のGPUメモリが必要です。
ただし、量子化技術(GGUF形式など)を用いると、大幅に必要リソースを削減できます。
Ollama、LM Studio、Text Generation WebUIなどのツールでシンプルに導入できるのも魅力です。
MistralとMixtralの特徴と適用シーン
Mistral AI社が提供するMistral 7Bモデルは、パラメータ数の割に高い性能を誇り、限られたリソースでも優れた結果を生み出せる「コストパフォーマンスの王者」とも言えます。
一方、同社のMixtralモデルはMixture of Experts(MoE)技術を採用し、複数の専門モデルを組み合わせることで効率的に高性能を実現しています。
Mistral 7Bは、ノートPCやエッジデバイスでの運用に適しており、16GB未満のGPUメモリでも動作可能です。
社内チャットボットや文書要約、簡易的なコード生成などの基本タスクに適しています。
一方、Mixtralは、より複雑な推論や高度な言語理解が必要なタスクに威力を発揮します。
財務分析や法務文書作成、研究論文の要約など、専門性の高い領域での活用が期待できます。
Mistral AIのモデルは商用利用にも柔軟なライセンスを持ち、特に欧州企業にとっては本拠地が欧州のAI企業という点でデータガバナンス面での安心感もあります。
GoogleのGemmaとMicrosoftのPhi-3の比較
より軽量なモデルをお探しなら、GoogleのGemma 2とMicrosoftのPhi-3が注目選択肢となります。
Gemma 2は9億と27億パラメータの2サイズが提供され、そのコンパクトさにもかかわらず優れた推論能力を持ちます。
一方、Phi-3はMicrosoftの最新小型モデルで、限られたリソースでも高い精度を実現します。
両モデルの最大の特徴は、消費リソースの少なさです。
8GB程度のGPUメモリ、あるいは高性能CPUのみでも動作可能なため、専用GPUサーバーを用意できない場合でも導入しやすいメリットがあります。
Gemma 2は特にチューニングのしやすさに優れ、自社データでのカスタマイズ性が高いのが特徴です。
一方、Phi-3は特に論理的推論やコード生成に強みを持ち、開発支援ツールとしての価値が高いモデルです。
どちらのモデルも、内部文書検索、簡易的な質問応答、初期段階のプロトタイピングなど、リソース効率を重視するシナリオに最適です。
大規模モデルの導入前に、これらの軽量モデルで概念実証(PoC)を行うことで、リスクを抑えつつローカルLLMの可能性を検証できます。
ローカルLLM導入のための技術環境構築ガイド

ローカルLLMの導入において最も重要なステップの一つが、適切な技術環境の構築です。
どれだけ優れたモデルを選んでも、それを効率的に動かすためのインフラが整っていなければ、期待通りのパフォーマンスは得られません。
ここでは、ローカルLLM運用のための技術環境構築における3つの重要要素について解説します。
必要なハードウェア構成(GPU/CPU/メモリ)
ローカルLLMの中核を担うハードウェアは、処理能力を決定づける重要な要素です。
まず最も重要なのがGPU(Graphics Processing Unit)です。
NVIDIA製のGPUが業界標準となっており、特にA100やV100などのデータセンター向けGPUや、RTX 3090/4090などのハイエンド消費者向けGPUが推奨されます。
GPUメモリ容量はモデルサイズに直結し、7B(70億)パラメータのモデルには最低16GB、70B(700億)パラメータのモデルなら80GB以上が理想的です。
CPU(Central Processing Unit)も重要な要素です。
GPUによる推論処理のボトルネックにならないよう、データ前処理や入出力処理を効率的に行える高性能CPUが必要です。
Intel Xeon、AMD EPYCシリーズなどのサーバー向けCPU、または高性能デスクトップCPUを推奨します。
RAM(システムメモリ)もモデル実行のための重要な要素で、最低32GB、理想的には64GB以上を確保すると安定した運用が可能です。
特にGPUメモリが限られている場合、システムRAMとのデータ転送が頻繁に発生するため、十分な容量が必要になります。
Ollama・LM Studio・Hugging Faceなど実行環境の選択
ハードウェアが揃ったら、次はLLMを実行するためのソフトウェア環境を選定します。
現在、いくつかの主要な選択肢があり、それぞれに特徴があります。
Ollamaは、コマンドラインから簡単にLLMをダウンロードして実行できるツールで、初心者にも扱いやすいのが特徴です。
「ollama run llama3」のような簡単なコマンド一つでモデルをダウンロードから実行まで完結できるため、導入の敷居が低く、Windows/Mac/Linuxの全てのプラットフォームに対応しています。
LM Studioは、GUIベースのツールで、モデルの管理や設定、チャットインターフェースまでを提供し、プログラミング知識がなくても操作可能です。
複数のモデルを簡単に切り替えながら比較できる点が強みです。
Hugging Face Transformersは、より柔軟なカスタマイズを求める場合に適したPythonライブラリで、多様なモデルアーキテクチャに対応し、細かなチューニングが可能です。
ただし、ある程度のプログラミングスキルが必要となります。
これらのほか、llama.cppは、C++で書かれた軽量な推論エンジンで、特に量子化したモデルを効率的に実行できるため、限られたリソースでの運用に適しています。選択の際は、自社の技術スキルとニーズに合わせて最適なツールを選定しましょう。
量子化技術を活用したリソース最適化手法
大規模言語モデルは膨大なリソースを必要としますが、量子化技術を活用することで、限られたハードウェアでも効率的な運用が可能になります。
量子化とは、モデルの重みを表現するために使われる数値精度を下げる技術です。
例えば、32ビット浮動小数点(FP32)で表現されていた値を、16ビット(FP16)、8ビット(INT8)、あるいは4ビット(INT4)に変換することで、メモリ使用量を大幅に削減できます。
代表的な量子化形式としてGGUF(GPT-Generated Unified Format)があり、llama.cppなどのツールと組み合わせることで、本来80GBのGPUメモリが必要なモデルを16GB程度で動かすことも可能になります。
量子化には一般的に精度とパフォーマンスのトレードオフがありますが、最近の技術進化により、その差は小さくなってきています。
特にAWQやQLoRAなどの新しい手法は、精度をほとんど落とさずに大幅なメモリ削減を実現しています。
また、量子化と並行して、プルーニング(不要なパラメータの削除)や知識蒸留(大きなモデルの知識を小さなモデルに移転)など、様々なモデル軽量化技術も活用すると、より効率的な運用が可能になります。
ローカルLLM実装の5ステップ実践ガイド
ローカルLLMの導入は、綿密な計画と段階的なアプローチが成功の鍵となります。
技術的な面だけでなく、組織のニーズや目標に合致させることが重要です。
ここでは、ローカルLLMを自社環境に実装するための5つの具体的ステップを順を追って解説します。
これらのステップを踏めば、スムーズにローカルLLMを導入できます。
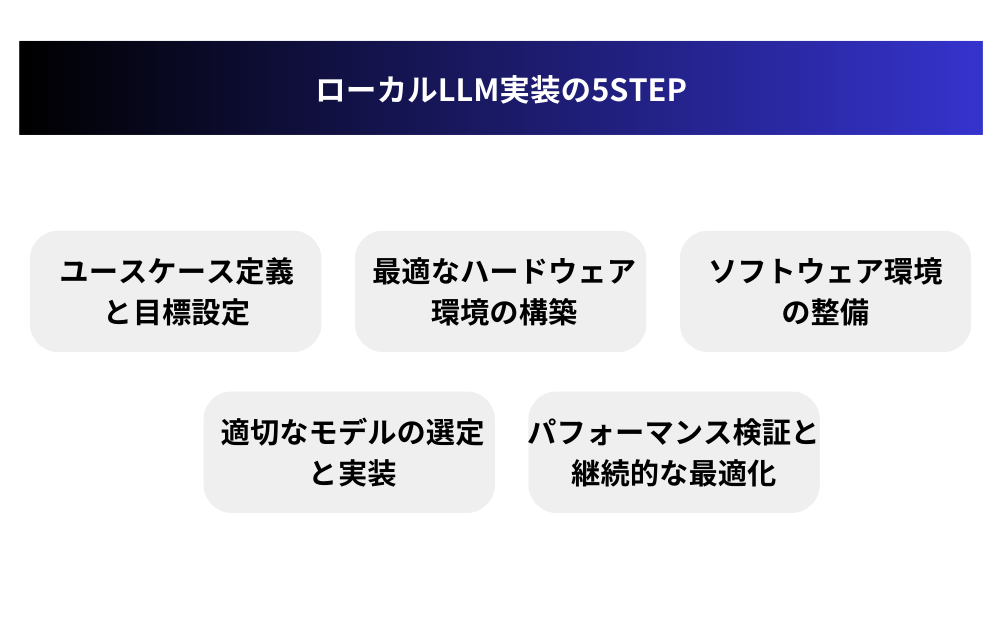
ステップ1:ユースケース定義と目標設定
ローカルLLM導入の第一歩は、明確なユースケースと具体的な目標の設定です。
「なぜローカルLLMが必要なのか」「どのような業務課題を解決したいのか」を具体化しましょう。
例えば、社内ナレッジベースの検索・要約システム構築、機密文書の分析、カスタマーサポートの自動化など、具体的なユースケースを特定します。
また、定量的な成功指標(KPI)を設定することも重要です。
応答時間の短縮率、人的リソースの削減量、業務処理速度の向上など、測定可能な目標を設定することで、導入後の効果検証が容易になります。
さらに、プライバシー要件や規制遵守事項も明確にし、技術的な実装計画だけでなく、組織的な受け入れ態勢やユーザートレーニング計画も含めた総合的なロードマップを策定しましょう。
ステップ2:最適なハードウェア環境の構築
ステップ1で定義したユースケースに基づき、必要なハードウェア環境を構築します。
まず、使用予定のモデルサイズと同時利用ユーザー数を考慮して、必要なスペックを算出します。
小規模な実証実験なら、RTX 4090搭載のワークステーション1台から始めることも可能です。
本格導入では、複数GPUを搭載したサーバーの構築を検討しましょう。
特に重要なのがGPUの選定です。
NVIDIA A100/H100などのデータセンター向けGPUは高価ですが、安定性と処理能力に優れています。
コスト重視なら、RTXシリーズの消費者向けGPUも選択肢となります。
また、冗長性と拡張性を考慮したシステム設計も重要です。
ハードウェア障害に備えたバックアップ体制や、将来的な拡張を見据えたスケーラブルな設計を心がけましょう。
初期段階では、クラウドGPUインスタンスでテスト環境を作り、要件を検証してから物理サーバーへの投資を判断するアプローチも効果的です。
ステップ3:ソフトウェア環境の整備
ハードウェアが準備できたら、次はソフトウェア環境の構築に移ります。
基本的なステップは以下の通りです。
まず、オペレーティングシステムをインストールします(Ubuntu等のLinuxディストリビューションが推奨)。
次に、NVIDIA GPUを使用する場合は、CUDA ToolkitとcuDNNをインストールし、GPUドライバを最適化します。
その後、Python環境の構築として、Anacondaやminicondaでの仮想環境作成が推奨されます。
これにより依存関係の管理が容易になります。必要なライブラリ(PyTorch、Transformers、sentencepiece等)をインストールし、必要に応じてバージョンを固定しておくことが重要です。
特にPyTorchとCUDAのバージョン互換性には注意が必要です。
最後に、モデルの実行環境を選択します。
初心者向けにはOllamaやLM Studioなどの直感的なツール、より柔軟な制御が必要な場合はHugging Faceのライブラリ、リソース効率を重視するならllama.cppなどが選択肢となります。
どのアプローチを選んでも、一貫した環境構築と適切なバージョン管理が重要です。
ステップ4:適切なモデルの選定と実装
ソフトウェア環境が整ったら、ユースケースに最適なモデルを選定し、実装します。
モデル選びでは、タスクの複雑さ、必要な言語能力、リソース制約のバランスを考慮します。
汎用的なタスクにはLlama 3や Mixtralが適していますが、特定ドメインに特化したい場合は、業界特化モデルや、自社データでのファインチューニングも検討します。
実装の第一歩は、選択したモデルをダウンロードすることです。
Hugging Face、Modelscope、各開発元の公式リポジトリなどから入手可能です。
大規模モデルは数十GBになるため、高速なネットワーク環境が理想的です。
ダウンロードしたモデルは、必要に応じて量子化(GGUF、GPTQ、AWQなど)して、メモリ使用量を削減します。
次に、推論パイプラインを構築します。
プロンプトテンプレートの設計、トークン制限の設定、温度などのパラメータ調整を行い、モデル出力の品質を最適化します。
さらに、RAG(検索拡張生成)やエージェントなどの拡張機能を実装することで、モデルの能力を大幅に向上させることができます。
最後に、APIエンドポイントやWebインターフェースを設計し、エンドユーザーが利用しやすい形で提供します。
ステップ5:パフォーマンス検証と継続的な最適化
ローカルLLMの実装後、継続的なパフォーマンス検証と最適化が重要です。
まず、定量的・定性的な評価指標を設定してベンチマークを実施します。
応答時間、処理スループット、メモリ使用量などの技術的指標と、出力の正確性、一貫性、有用性などの品質指標の両面から評価しましょう。
実運用データに基づく継続的なモニタリングシステムを構築し、パフォーマンスの低下や異常を早期に検出できる体制を整えることも重要です。
定期的なユーザーフィードバックを収集し、実際の利用者視点での改善点を把握します。
特に初期段階では、エンドユーザーからの具体的なフィードバックが貴重な最適化の手がかりとなります。
技術的な最適化としては、プロンプトエンジニアリングの改善、パラメータ調整、バッチ処理の最適化などが効果的です。
また、新しいモデルや技術が登場した際の更新計画も策定しておきましょう。
ローカルLLMは「一度導入して終わり」ではなく、継続的な改善サイクルを通じて価値を高めていくものです。
組織内でのナレッジ共有や成功事例の横展開を促進し、活用範囲を徐々に拡大していくことで、投資対効果を最大化できます。
まとめ:ローカルLLMで安全かつコスト効率の高いAI基盤を構築しよう

ローカルLLMは、データの安全性やコスト効率、業務特化の自由度など、企業にとって多くのメリットを持つAI基盤です。
特に機密性や応答速度が求められる現場では、クラウド型では実現できない価値を提供します。
導入には一定の技術的ハードルがあるものの、段階的に取り組むことで着実に成果を出せます。
自社に最適なモデルや構成を選びながら、安全かつ柔軟なAI活用を進めていきましょう。
【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


