
Gemini 2.5 Flashとは?機能や使い方、料金を徹底解説
この記事でわかること
- Gemini 2.5 Flashとは
- Gemini 2.5 Flashの機能や具体的な使い方、料金、無料での利用方法など
- Gemini 2.5 Flashの2.0 flashからの進化ポイントや主要AIモデルとの徹底比較

Google初の「完全ハイブリッド推論モデル」として2025年4月17日に公開されたGemini 2.5 Flashが、生成AI活用の新たな可能性を切り開いています。推論(思考)機能のオン/オフを自在に切り替えられる柔軟性と、細かく思考予算を設定できる制御性が特徴のこのモデルは、高速処理と深い思考力の両立を実現。コストパフォーマンスも優れており、企業のAI導入を加速させる強力なツールとなりそうです。本記事では、Gemini 2.5 Flashの革新的機能や使い方、活用シーンを徹底解説します。

目次
Gemini 2.5 Flashとは|Google初の完全ハイブリッド推論モデル
※引用:https://developers.googleblog.com/en/start-building-with-gemini-25-flash/
Googleは2025年4月17日、新たな生成AIモデル「Gemini 2.5 Flash」のプレビュー版をリリースしました。このモデルはGoogleが初めて開発した「完全ハイブリッド推論モデル」と位置付けられており、高度な推論能力と処理速度、コスト効率を兼ね備えた画期的なAIモデルです。
推論能力とコスト効率を両立する新世代AI
Gemini 2.5 Flashは、好評を博していた2.0 Flashの基盤をベースに構築されています。2.0 Flashの高速性を保ちながらも、推論能力を大幅に向上させたことが最大の特徴です。AIモデルにおいて「速度」と「推論の深さ」は通常トレードオフの関係にありますが、Gemini 2.5 Flashはその両立を実現しています。
入力コストは$0.15/1Mトークン、出力コストは推論を使用しない場合は$0.60/1Mトークン、推論を使用する場合は$3.50/1Mトークンと設定されています。この価格設定により、用途に応じて最適なコスト効率で利用できる柔軟性を提供しています。他社の高性能AIモデルと比較しても、パフォーマンスあたりのコストが最も優れているとGoogleは主張しています。
「thinking」機能で実現する高度な問題解決能力
Gemini 2.5モデルの核となる「thinking(思考)」機能は、即座に出力を生成するのではなく、いったん「思考」のプロセスを実行することで、より深い理解と分析を可能にします。これにより、プロンプトを深く理解し、複雑なタスクを分解して、より正確で包括的な回答を計画できるようになります。
thinkingモードが特に効果を発揮するタスク
・複雑な数学的問題の解決
・多段階の推論を必要とする質問への対応
・高度な分析が求められる研究課題
・構造化されたデータからのパターン抽出
・論理的整合性の高い文書作成
実際、LMArenaのHard Promptsベンチマークにおいて、Gemini 2.5 FlashはGemini 2.5 Proに次ぐ高いパフォーマンスを記録しています。
Gemini 2.5シリーズにおける位置づけと特徴
Gemini 2.5シリーズの中で、Flashモデルは「高速処理と推論のバランス」に特化したモデルとして位置づけられています。最上位モデルの2.5 Proが最高の推論能力を提供する一方で、2.5 Flashはコストパフォーマンスを重視するユースケースに最適化されています。
Googleの発表によると、2.5 Flashは「パレート最適」なモデルとして設計されており、品質とコストのバランスが絶妙なポイントで最適化されています。言い換えれば、このコスト帯で最高の性能を発揮するように調整されており、コスト制約のある実務利用に適しています。
従来のモデルが固定の性能特性を持っていたのに対し、2.5 Flashでは推論の使用有無や深さを自由に調整できるため、1つのモデルでさまざまなユースケースに対応可能になりました。これにより、モデルの使い分けに悩む必要がなくなり、開発と運用の効率化が期待できます。
Gemini 2.5 Proについては『Gemini 2.5 Proとは?機能や使い方、料金を徹底解説』の記事で詳しく解説しております。
Gemini 2.5 Flashが実現する4つの革新機能

Gemini 2.5 Flashは、従来のAIモデルとは一線を画す革新的な機能を複数備えています。これらの機能により、ユーザーは用途に応じて最適な設定で利用でき、コストと性能のバランスを自在に調整することが可能になりました。ここでは、Gemini 2.5 Flashが実現する4つの革新機能について詳しく解説します。
推論モードのオン/オフを自由に切り替え
Gemini 2.5 Flashの最大の特徴は、業界初となる「完全ハイブリッド推論モデル」であることです。ユーザーは推論(思考)モードのオン/オフを自由に切り替えることができます。これにより、シンプルな質問には高速な応答を、複雑な問題には深い思考に基づいた回答を、同じモデルで使い分けられるようになりました。
推論モードをオフにした場合、Gemini 2.0 Flashと同等の高速レスポンスが得られます。例えば「ありがとうをスペイン語で」や「カナダには何州ありますか?」といった単純な質問では、推論は不要で即座に正確な回答が可能です。一方、複雑な計算や多段階の分析が必要な質問では、推論モードをオンにすることで質の高い回答を得られます。
柔軟な思考予算設定で効率とコストを最適化
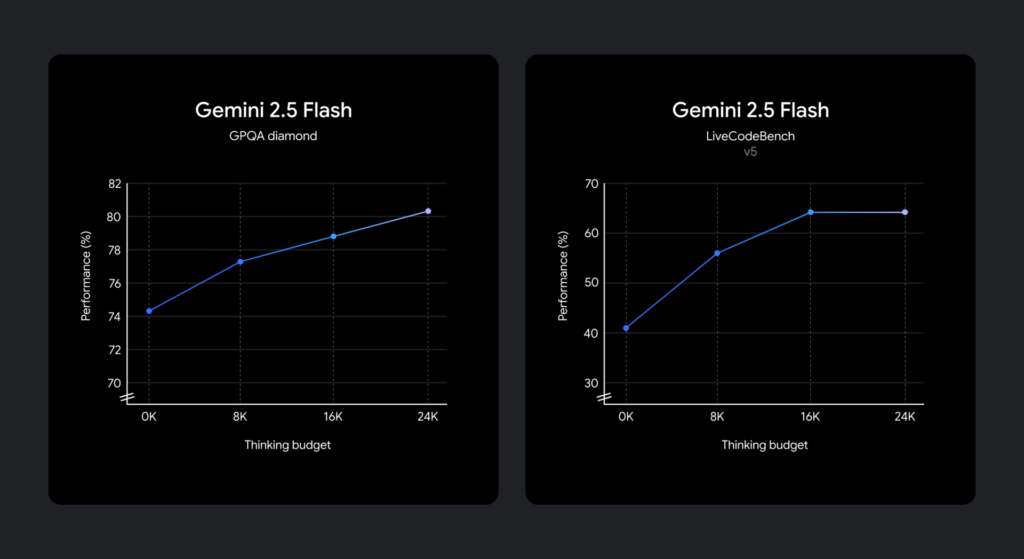
Gemini 2.5 Flashでは、「思考予算(thinking budget)」という概念が導入されました。これはモデルが思考中に生成できるトークンの最大数を指定するもので、0から24,576トークンの範囲で設定可能です。
思考予算の主な特徴
・予算範囲:0〜24,576トークンで自由に設定可能
・高予算設定:より多くの推論を実行し、高品質な回答を生成
・低予算設定:応答時間の短縮とコスト削減が可能
・必要分使用:設定した上限までを必要に応じて使用
・自動判断:プロンプトの複雑さに基づき適切な思考量を決定
Googleによれば、モデルは与えられたプロンプトに対してどれだけの思考が必要かを自動的に判断するようトレーニングされているため、実際のタスクの複雑さに基づいて適切な思考量を決定します。
下記の通り、思考予算が増加するにつれて推論の質が向上します。
※引用:https://developers.googleblog.com/ja/start-building-with-gemini-25-flash/
業界最高水準のコストパフォーマンス
※引用:https://developers.googleblog.com/en/start-building-with-gemini-25-flash/
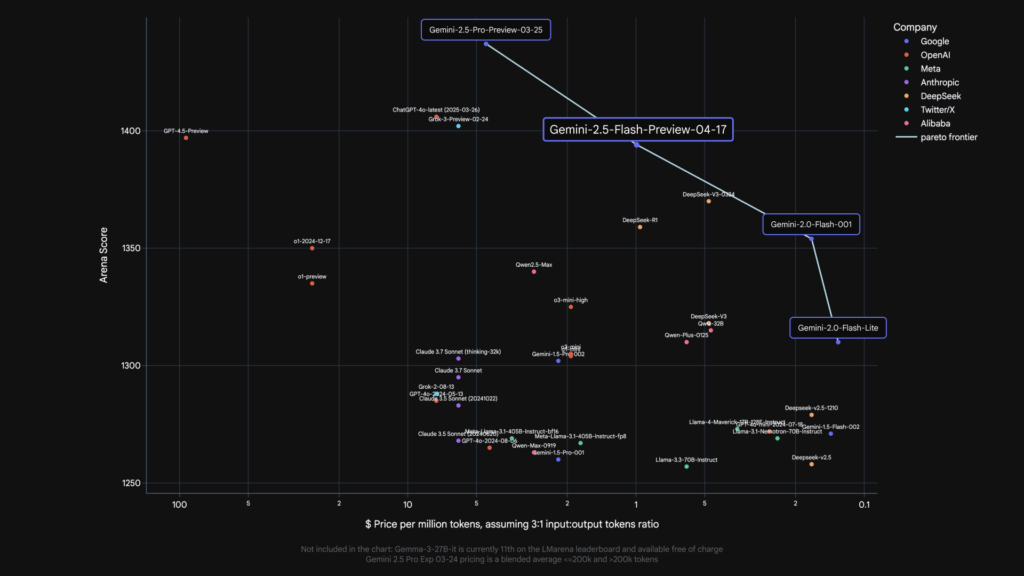
Gemini 2.5 Flashは、性能とコストのバランスにおいて業界をリードする位置にあります。入力コストは$0.15/1Mトークン、出力コストは推論を使用しない場合$0.60/1Mトークン、推論を使用する場合$3.50/1Mトークンという価格設定となっています。
競合モデルと比較すると、同等の性能を持つモデルの中で最もコスト効率が高いことがわかります。例えば、Claude 3.7 SonnetやGrok 3 Betaの入力コストは$3.00/1Mトークン、出力コストは$15.00/1Mトークンであり、Gemini 2.5 Flashの方が大幅に低コストです。
Googleが公開したベンチマークデータによれば、「Humanity’s Last Exam」テストにおいて12.1%のスコアを達成しており、これはGemini 2.0 Flashの5.1%から大幅に向上しています。このように、コストを抑えながらも性能が向上している点が特筆すべき特徴です。
複雑な多段階推論への優れた対応能力
Gemini 2.5 Flashは、複雑な多段階推論を必要とするタスクに優れた対応能力を示します。例えば、「長さL=3mのカンチレバービームは、長方形断面(幅b=0.1m、高さh=0.2m)で鋼製(弾性率E=200 GPa)です。ビーム全体に均一に分布した荷重w=5 kN/mが作用し、自由端に点荷重P=10 kNが作用しています。最大曲げ応力(σ_max)を計算してください。」といった工学問題や、複雑なアルゴリズムの設計など、高度な推論能力を要するタスクを適切に処理できます。
また、コードの生成においても、単純な関数だけでなく、再帰処理や複雑なアルゴリズムなど、多段階の論理を必要とするコード生成に強みを発揮します。Googleの示したライブコードベンチにおいても、Gemini 2.0 Flashの34.5%に対して、2.5 Flashは63.5%というスコアを達成しています。
このように、Gemini 2.5 Flashは単一のモデルでありながら、シンプルな応答から複雑な推論まで幅広いニーズに対応できる柔軟性を兼ね備えています。これにより、異なる難易度のタスクごとに別々のモデルを使い分ける必要がなくなり、開発・運用の効率化が期待できます。
Gemini 2.5 Flashと主要AIモデルの徹底比較

生成AIモデルの選定において、性能とコストのバランスは重要な判断基準となります。ここでは、Gemini 2.5 Flashと他の主要AIモデルを様々な観点から比較し、その位置づけを明確にします。
Gemini 2.0 Flashからの進化ポイント
Gemini 2.5 Flashは、前モデルである2.0 Flashからいくつかの重要な点で進化しています。最も顕著な違いは推論(思考)機能の追加であり、複雑な問題に対する解決能力が大幅に向上しました。
主要ベンチマークでの性能向上
・Humanity’s Last Exam: 5.1% → 12.1%(2倍以上のスコア向上)
・GPQA diamond: 60.1% → 78.3%(科学的理解力の向上)
・AIME 2025: 27.5% → 78.0%(数学的問題解決能力の大幅向上)
・AIME 2024: 32.0% → 88.0%(より一貫した数学能力)
・LiveCodeBench v5: 34.5% → 63.5%(コード生成能力の倍増)
特に顕著なのはコード生成能力で、「LiveCodeBench v5」においては34.5%から63.5%へとほぼ2倍の性能向上を実現しています。これらの結果は、単に「思考」機能を追加しただけでなく、モデル自体の基礎的な性能も向上していることを示しています。
価格面では入出力コストは据え置きながら、オプションで推論機能を使用する場合にのみ追加コストが発生する構造となっており、ユーザーにとって柔軟な選択肢を提供しています。
Gemini 2.0 Flashについては『Gemini 2.0 Flashとは?機能と利用方法を画像付きで解説』の記事で詳しく解説しております。
Claude 3.7やChatGPTとの性能差
※引用:https://developers.googleblog.com/en/start-building-with-gemini-25-flash/
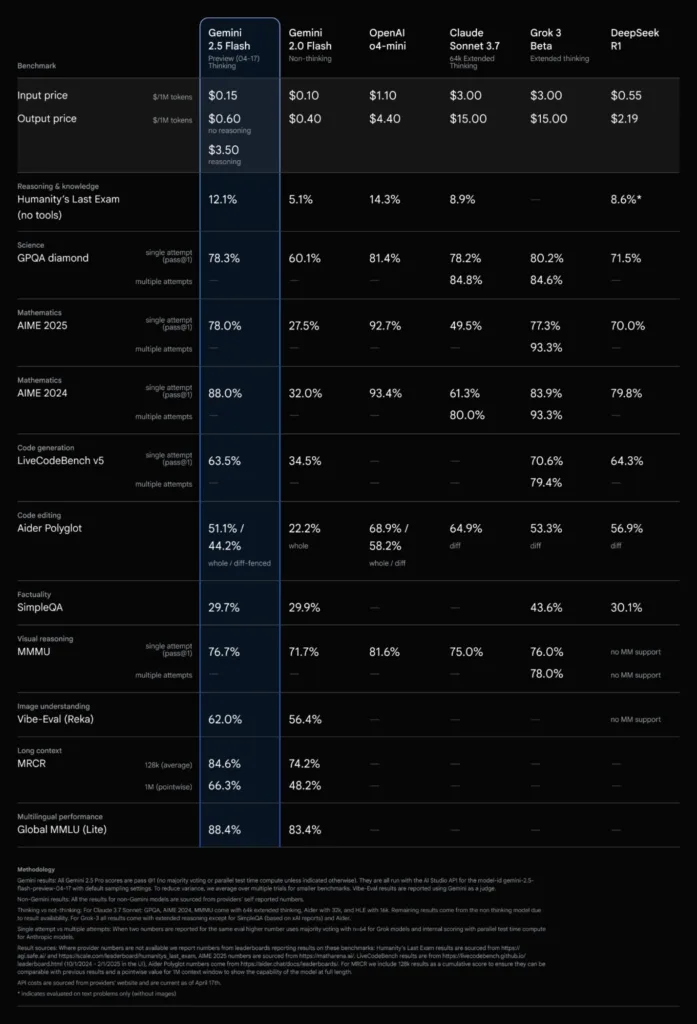
Gemini 2.5 FlashとAnthropicのClaude 3.7 Sonnet、OpenAIのo4-mini、xAIのGrok 3 Betaなど、主要な競合モデルとの性能比較も興味深い結果を示しています。
「Humanity’s Last Exam」においては、Claude 3.7 Sonnetの8.9%、Grok 3 Betaの数値は非公開ですが、DeepSeek R1の8.6%と比較して、Gemini 2.5 Flashの12.1%は優位性を示しています。数学的問題解決能力を測る「AIME 2025」では、Claude 3.7 Sonnetの49.5%に対してGemini 2.5 Flashは78.0%と大きく上回っています。
一方、科学的理解を測る「GPQA diamond」では、Claude 3.7 Sonnetの78.2%、Grok 3 Betaの80.2%に対し、Gemini 2.5 Flashは78.3%とほぼ同等のスコアを示しています。コード生成能力においても、Grok 3 Betaの70.6%に近い63.5%を達成しており、高価格帯モデルに迫る性能を持っています。
OpenAIのo4-miniは「AIME 2025」で92.7%と最高のスコアを示していますが、入力コスト$1.10、出力コスト$4.40と、Gemini 2.5 Flashより高額な価格設定となっています。それぞれのモデルは得意分野が異なるため、用途に応じた選択が重要です。
Gemini 2.5 Flashを無料で使う方法を画像付きで解説
Gemini 2.5 Flashは、Google AI StudioやVertex AI、Geminiアプリから利用できます。それぞれのプラットフォームでの具体的な使用方法を解説し、推論機能の設定方法や最適な活用テクニックを紹介します。初めて利用する方でも理解しやすいように説明していきます。
Geminiアプリでの使用方法
Geminiアプリは、モバイルやWebブラウザから簡単にGemini 2.5 Flashにアクセスできる最も手軽な方法です。初めての方でも直感的に操作できるインターフェースが特徴です。Gemini 2.5 Flashを無料で利用することが可能です。
Geminiアプリでの基本操作手順:
・起動:Geminiアプリを起動
・モデル選択:左上のドロップダウンメニューから「Gemini 2.5 Flash」を選択
チャット欄にプロンプトを入力すれば利用できます、
Geminiのアプリでは現状、推論予算は調整できない仕様になっています。
Google AI Studioでの使用方法
Google AI Studioは、開発者向けのより高度な環境で、APIへのアクセスやプロンプトのテスト、微調整などが可能なプラットフォームです。Gemini 2.5 Flashを本格的に活用したい開発者に適しています。Gemini 2.5 Flashを無料で利用することが可能です。
Google AI Studioの使用手順:
・アクセス:Google AI Studioにアクセス
・ログイン:Googleアカウントでログイン
・モデル選択:画面上部のドロップダウンから「Gemini 2.5 Flash preview-04-17」を選択
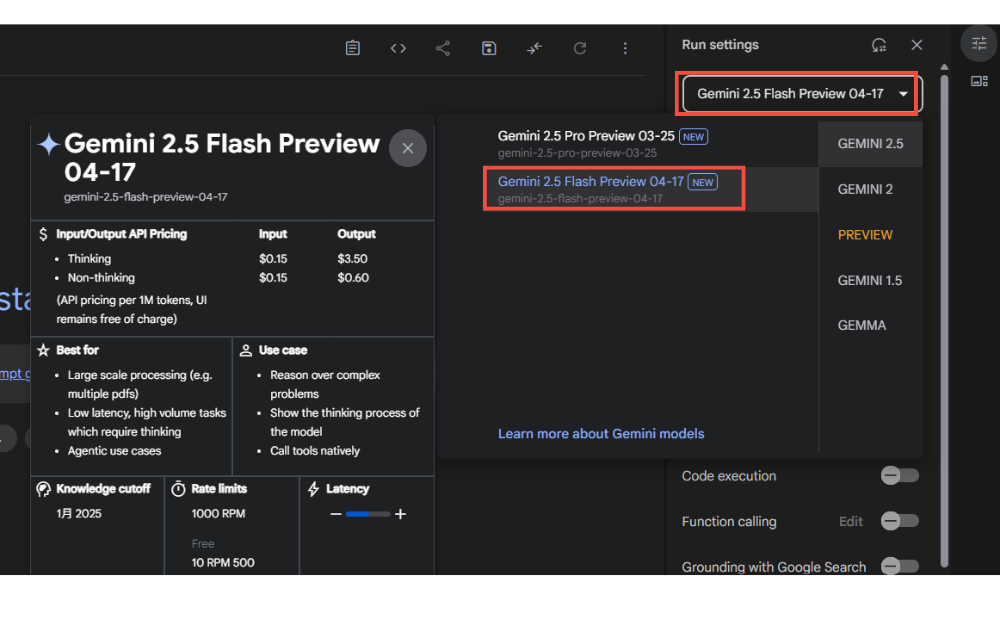
・推論設定:画面右側の設定パネルから「Thinking mode」のオン・オフの切り替えが可能
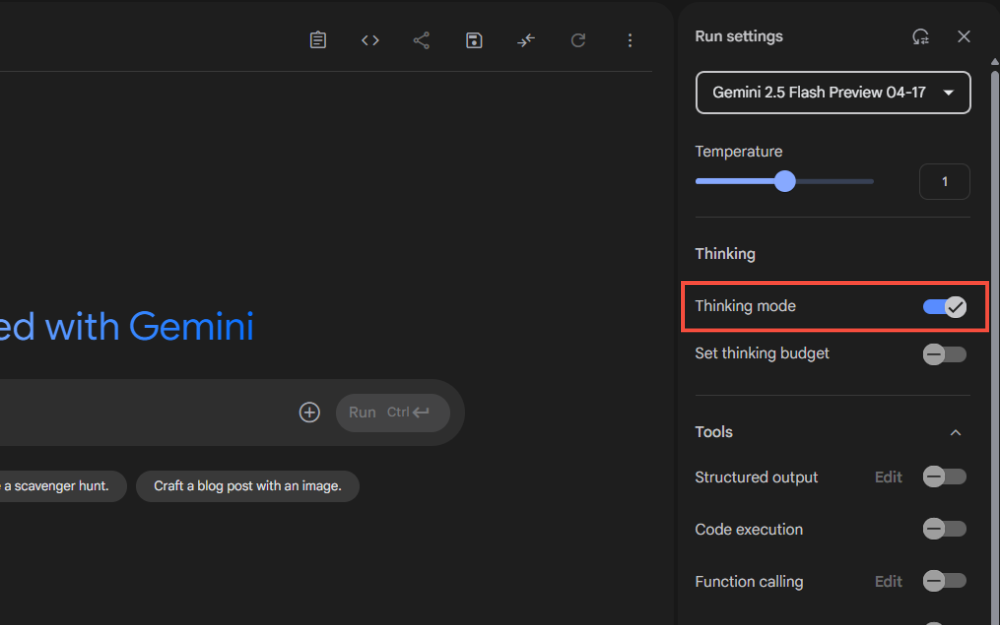
・予算設定:スライダーで必要な推論予算を調整
このスライダーを動かして、必要な推論予算を設定します。予算を増やすほど、モデルはより深い推論を行いますが、レスポンス時間も長くなる点に注意が必要です。
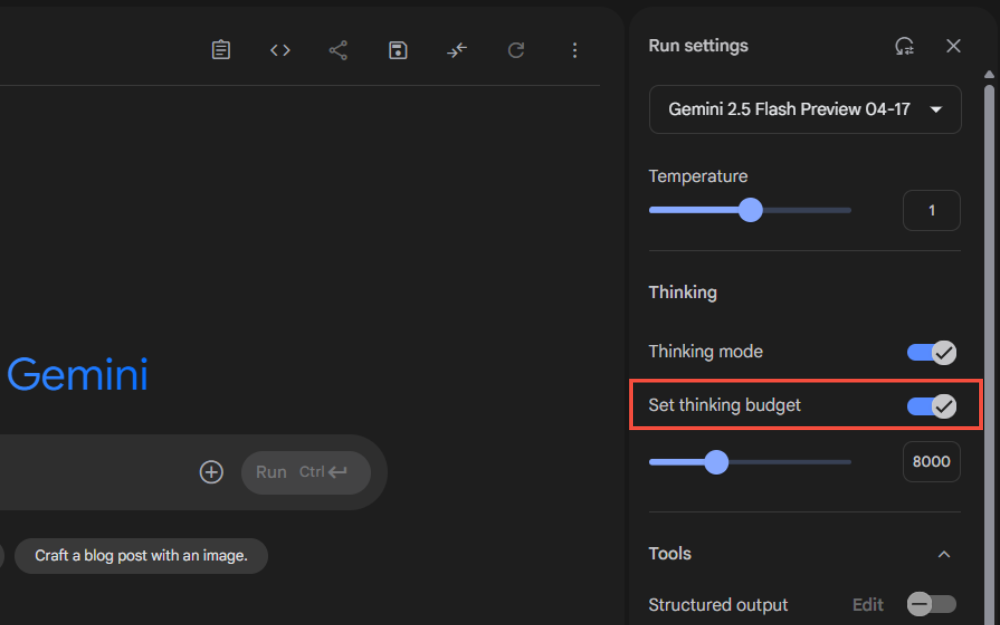
設定が完了したらプロンプトを入力すれば利用可能です。
Google AI Studioについては『Google AI Studioとは?始め方や何ができるかを解説【画像付き】』の記事で詳しく解説しております。
Vertex AIでの効率的な実装方法
Google Cloud Platformの機械学習サービスであるVertex AIでも、Gemini 2.5 Flashを利用できます。Vertex AIは、エンタープライズレベルの本格的なAI実装に適しており、高度なスケーラビリティやセキュリティ機能を備えています。
Vertex AIでのGemini 2.5 Flash導入手順
・前提条件:GCPアカウントとプロジェクトの準備
・アクセス:Vertex AI consoleにアクセス
・選択:「Generative AI Studio」を選択
・モデル選択:モデルギャラリーから「Gemini 2.5 Flash preview-04-17」を選択
・推論設定:思考予算をスライダーで設定
・安全性設定:各種フィルターや温度設定をカスタマイズ
・実装:REST APIまたはクライアントライブラリを使用して統合
Vertex AIの特長は、企業の本番環境での利用に適した豊富な機能です。思考予算の設定は他のプラットフォームと同様にスライダーで行えますが、より詳細な設定オプションも利用可能です。例えば、安全性フィルターの調整やレスポンスの温度設定など、より細かな制御が可能です。
Vertex AIでは、推論予算の設定に加えて、モデルの動作を最適化するための様々なパラメータが用意されています。例えば、安全性フィルターの強度調整、出力のランダム性を制御する温度設定、生成するトークン数の上限設定などがあります。これらを組み合わせることで、用途に最適化されたAIレスポンスを実現できます。
Gemini 2.5 Flashの実践的活用シーン
Gemini 2.5 Flashの革新的な機能を理解したところで、次はこのモデルがビジネスシーンでどのように活用できるのかを見ていきましょう。推論機能とコスト効率の高さを活かした実践的な活用方法を知ることで、企業における導入効果を最大化することができます。
ビジネス課題解決に適した具体的ユースケース
Gemini 2.5 Flashは、その柔軟な推論能力とコスト効率の高さから、様々なビジネス課題の解決に適しています。特に以下のようなシーンでの活用が効果的です。
ビジネスにおける主要活用シーン
・カスタマーサポート:単純な問い合わせには高速応答、複雑な問題には深い思考を適用
・データ分析・レポート作成:大量データからの洞察抽出とトレンド予測
・プログラミング支援:アルゴリズム設計や複雑なバグ解決など多段階推論が必要なタスク
・マーケティングコンテンツ:ターゲット心理分析と効果的なメッセージ構築
・社内ナレッジ管理:膨大な情報から文脈を理解した知識抽出と整理
カスタマーサポートの強化では、日常的な問い合わせには推論機能をオフにして高速応答を実現し、複雑な問題解決が必要な場合のみ推論機能をオンにするという使い分けが可能です。これにより、対応時間の短縮とユーザー満足度の向上を同時に達成できます。
また、マーケティングコンテンツの作成においても、ターゲットオーディエンスの心理分析や効果的なメッセージ構築など、戦略的思考を要する作業に推論機能を活用することで、より説得力のあるコンテンツ制作が可能になります。
推論予算の最適設定による効果最大化
Gemini 2.5 Flashの効果を最大化するためには、用途に応じた推論予算の適切な設定が鍵となります。ユースケース別の最適な設定指針を紹介します。
タスク難易度別の推論予算設定ガイド
・シンプルなタスク(0トークン):FAQの自動応答、基本的な製品情報提供
・低難度タスク(〜500トークン):簡単な分析、短文ライティング、基本的な質問応答
・中難度タスク(500〜1,000トークン):確率計算、スケジュール最適化、中規模データ分析
・高難度タスク(1,000〜5,000トークン):多段階論理思考、複雑な意思決定支援、詳細な市場分析
・最高難度タスク(5,000〜24,576トークン):工学的計算、複雑なアルゴリズム設計、多面的なビジネス戦略策定
実務では、まず低い推論予算から始めて、結果の質に応じて段階的に予算を増やすアプローチが効率的です。これにより、各タスクに必要最小限のコストで最適な結果を得ることができます。
まとめ:Gemini 2.5 Flashで次世代のAI活用を加速しよう
Gemini 2.5 Flashは、Googleが提供する初の完全ハイブリッド推論モデルとして、生成AIの新たな可能性を開く画期的なモデルです。適切な推論予算設定により効果を最大化し、業務プロセスの効率化と質の向上を同時に実現するGemini 2.5 Flashを活用して、次世代のAI活用を加速させていきましょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


