
機械学習とディープラーニングの違い5選|目的別に最適技術がわかる選び方ガイド
この記事でわかること
- 機械学習とディープラーニングの導入コストや必要な人材・設備
- 自社の課題や目的に応じた技術選定のポイント
- 導入後の運用・保守体制やROIの測定方法

AI技術の発展が加速する中、「機械学習」と「ディープラーニング」という言葉をよく耳にするようになりました。
しかし、これらの技術の明確な違いや、ビジネスでどう使い分けるべきかを理解している方は意外と少ないのではないでしょうか。
本記事では、AIの専門家としての知見をもとに、機械学習とディープラーニングの本質的な違いを5つのポイントで解説します。
さらに、自社のプロジェクトにどちらの技術を採用すべきか、その判断基準や成功のためのノウハウまで、実践的な視点からご紹介します。
AI技術導入を検討されている方も、知識を深めたい方も、ぜひ参考にしてください。
目次 [hide]
機械学習とディープラーニングの違いを完全解説
AIブームが続く昨今、「機械学習」と「ディープラーニング」という言葉をよく耳にするようになりました。
しかし、これらの技術の違いを正確に理解している方は多くありません。
本記事では、AI導入を検討する企業担当者やエンジニアの方に向けて、両者の違いを明確に解説します。
AI技術における2つの技術の正確な位置づけ
まず、基本的な階層構造を理解しましょう。
人工知能(AI)は大きな概念であり、その中に「機械学習」という要素技術が含まれています。
そして「ディープラーニング」は機械学習の一種であり、より高度な処理を可能にする技術です。
機械学習とは、機械がデータから学習し、そのパターンや規則性を見つけ出して判断や予測を行う技術です。
一方、ディープラーニングは機械学習の発展形で、人間の脳の神経回路をモデルにした「ニューラルネットワーク」を多層化することで、より複雑なパターン認識を実現しています。
両者の関係は「AIという大きな円の中に機械学習という中円があり、その中にディープラーニングという小円がある」というイメージで捉えるとわかりやすいでしょう。
「教師あり・なし・強化学習」で理解する機械学習の本質
機械学習には大きく分けて3つの学習方法があります。
これを理解することで、機械学習の本質が見えてきます。
- 教師あり学習:正解(ラベル)付きのデータを使って学習する方法です。
例えば「この画像はリンゴです」「この画像はみかんです」というラベル付きのデータから学習し、新しい画像が何の果物かを判断できるようになります。 - 教師なし学習:正解のないデータから、システム自らがパターンや構造を見つけ出す学習法です。
例えば顧客データから似た嗜好を持つグループを自動的に分類するなどの用途に使われます。 - 強化学習:試行錯誤を繰り返し、報酬を最大化する行動を学習する方法です。
ロボット制御や囲碁AIなどに活用されています。
ディープラーニングはこれらの学習方法、特に教師あり学習の発展形として位置づけられますが、その学習プロセスはより複雑で高度です。
ニューラルネットワークに基づくディープラーニングの仕組み
ディープラーニングの核心は「多層ニューラルネットワーク」にあります。
これは人間の脳の神経細胞(ニューロン)の働きを模倣したモデルです。
基本的なニューラルネットワークは、入力層・隠れ層・出力層という3層構造を持ちますが、ディープラーニングでは「深層学習」という名前の通り、この隠れ層を何層も重ねることで複雑な情報処理を実現します。
各層のニューロンは前の層からの入力に「重み」を掛け、活性化関数を通して次の層に信号を送ります。
学習過程では、出力結果と期待される結果の誤差に基づいて各ニューロン間の重みを調整していきます。これを「誤差逆伝播法」と呼びます。
このような複雑なネットワーク構造により、ディープラーニングは人間が明示的に特徴を定義しなくても、データから自動的に特徴を抽出できるという大きな強みを持っています。
技術関係図でわかる「AI・ML・DL」の繋がり
これまでの説明を図式化して理解してみましょう。
【人工知能(AI)】
├── ルールベースAI(従来型AI)
└── 【機械学習(ML)】
├── 線形回帰/ロジスティック回帰
├── サポートベクターマシン
├── 決定木/ランダムフォレスト
├── クラスタリング(k-means等)
└── 【ディープラーニング(DL)】
├── CNN(畳み込みニューラルネットワーク)
├── RNN(再帰型ニューラルネットワーク)
├── LSTM(長短期記憶)
└── Transformer・・・など
このように、ディープラーニングは機械学習の一部であり、機械学習は人工知能の一部です。
各技術はそれぞれ得意分野と適した用途があります。
例えばシンプルな予測なら通常の機械学習で十分かもしれませんが、画像認識や自然言語処理などの複雑なタスクではディープラーニングが優れた性能を発揮します。
技術選択においては、解決したい問題の性質、利用可能なデータ量、必要な精度、コスト制約などを総合的に考慮することが重要です。
機械学習とディープラーニングの5つの決定的な違い
機械学習とディープラーニングは、どちらもAI技術の一種ですが、アプローチや適用範囲に大きな違いがあります。
ここでは、両者を明確に区別する5つの決定的な違いを解説します。
これらの違いを理解することで、ビジネスにおける技術選択の判断材料となるでしょう。
特徴量抽出:人間vs自動化の根本的な違い
機械学習とディープラーニングの最も本質的な違いは「特徴量抽出」のプロセスにあります。
機械学習では、人間が「どの特徴に注目すべきか」を事前に定義する必要があります。
例えば画像認識において「エッジ検出」や「色彩分布」など、人間がアルゴリズムに与える特徴量が結果を大きく左右します。
つまり、データの何に着目するかという「特徴エンジニアリング」が極めて重要なプロセスとなります。
一方、ディープラーニングでは、特徴量抽出自体をアルゴリズムが自動的に行います。
多層のニューラルネットワークを通じて、データの中から重要な特徴を自ら発見し学習していくのです。
これにより人間が気づかなかった微妙なパターンも捉えられるようになりました。
この違いにより、ディープラーニングは複雑なパターン認識において圧倒的な優位性を持っていますが、その分「なぜそのような判断をしたのか」の説明が難しくなるというトレードオフがあります。
必要データ量:少量でも学習vs大量データ必須
2つ目の大きな違いは、学習に必要なデータ量です。
機械学習は比較的少ないデータセットでも効果的に機能する場合があります。
数百〜数千件のデータでも、特徴量が適切に設計されていれば十分に実用的なモデルを構築できることが多いです。
一方、ディープラーニングは基本的に大量のデータを必要とします。
多層ニューラルネットワークの膨大なパラメータを適切に調整するためには、何万、何十万、時には何百万というデータポイントが必要になることもあります。
これはディープラーニングの「データ飢餓性」と呼ばれる特性です。
したがって、利用可能なデータ量が限られている場合は、従来の機械学習アルゴリズムの方が現実的な選択となるケースが多いでしょう。
データを大量に収集できる環境であれば、ディープラーニングの威力を発揮できる可能性が高まります。
処理能力:単純タスクvs複雑パターン認識
3つ目の違いは、処理できるタスクの複雑さにあります。
機械学習は、データの傾向が線形に近い比較的シンプルなタスクや、明確なルールで分類できる問題に適しています。
たとえば、「年収と勤続年数から住宅ローン審査の可否を判断する」といった比較的単純なパターンの予測に効果的です。
ディープラーニングは、非線形の複雑なパターン認識が得意です。
画像認識、音声認識、自然言語処理など、人間の知覚に近い複雑な判断を要する分野で圧倒的な強みを発揮します。
たとえば「猫の画像を認識する」というタスクでは、猫の形、模様、姿勢などの複雑な特徴を自動的に学習できます。
つまり、問題の複雑さに応じて適切な技術を選ぶことが重要です。
単純な分類や予測なら機械学習で十分ですが、人間の感覚に近い複雑な判断が必要なら、ディープラーニングの力が必要になるでしょう。
学習時間とコスト:即効性vs長期的投資
4つ目の違いは、実装にかかる時間とコストです。
機械学習モデルは、比較的短時間で開発・学習・デプロイできることが多く、コンピューティングリソースの要件も控えめです。
多くの場合、標準的なPCやクラウドの小規模インスタンスでも十分に動作します。
これにより、開発コストと運用コストを抑えることができます。
対照的に、ディープラーニングモデルの学習には膨大な計算リソースと時間を要します。
GPUやTPUなどの専用ハードウェアが必要になることも多く、学習に数日から数週間かかることもあります。
また、専門知識を持つ人材も必要となるため、人的コストも高くなりがちです。
この違いは、プロジェクトの予算や期間の制約によって、技術選択に大きな影響を与えます。
短期間で成果を出したい場合や、限られた予算内で実装したい場合は、機械学習が現実的な選択肢となるでしょう。
ブラックボックス性:説明可能性の比較
5つ目の違いは、モデルの「説明可能性」です。
機械学習、特に決定木やランダムフォレストなどのアルゴリズムは、どのような特徴が判断に影響したかを比較的容易に説明できます。
例えば「年齢と購買履歴のこの特徴が、この顧客が高額商品を購入する確率を高めている」などの形で結果を解釈できます。
一方、ディープラーニングは「ブラックボックス問題」と呼ばれる課題を抱えています。
多層ニューラルネットワークの内部で何が起きているのかを人間が理解しやすい形で説明することが非常に困難なのです。
「なぜその判断に至ったのか」の説明が難しいため、医療診断や金融審査など、説明責任が重要な分野での利用には慎重な検討が必要です。
近年は「説明可能なAI(XAI)」の研究も進んでいますが、現状ではディープラーニングの判断プロセスの透明性は機械学習に比べて低いと言わざるを得ません。
導入判断のための比較:メリットとデメリット
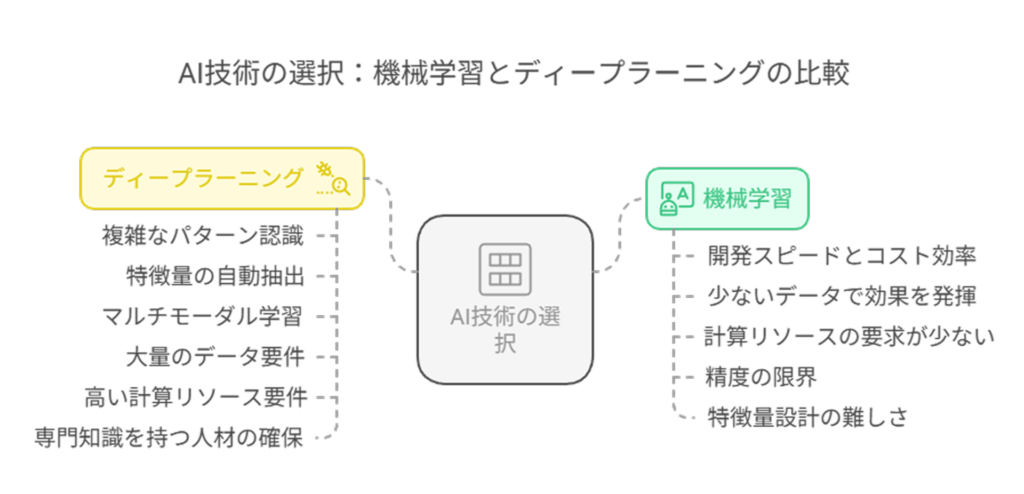
企業がAI技術を導入する際、機械学習とディープラーニングのどちらを選ぶべきか、という判断は非常に重要です。
ここでは、ビジネス面から見た両者のメリットとデメリットを比較し、適切な選択のための指針を提供します。
機械学習が優れる状況:低コストで迅速な成果を求める場合
機械学習が特に優れているのは、以下のようなケースです。
まず、開発スピードとコスト効率の面で大きなメリットがあります。
機械学習モデルは比較的短期間で開発・導入が可能であり、専門的な知識を持つ人材も比較的確保しやすい状況にあります。
また、データサイエンスの知識を持つビジネスパーソンでも、既存のライブラリやフレームワークを活用すれば導入できるケースも増えています。
次に、少ないデータでも効果を発揮できる点も大きな強みです。
新規事業や実績データが少ない分野でも、数百〜数千件程度のデータがあれば実用的なモデルを構築できることが多いです。
これは、ビジネスの初期段階や、データ収集が困難な領域において特に重要な利点となります。
さらに、計算リソースの要求が比較的少ないため、既存のITインフラを活用できることも多く、追加投資を抑えられる点も見逃せません。
クラウドサービスの小規模インスタンスや、場合によっては標準的なオンプレミスサーバーでも十分対応できるケースがあります。
機械学習の落とし穴:精度の限界とは
一方で、機械学習にも注意すべき限界があります。
最も大きな問題は、複雑なパターン認識において精度の限界が生じることです。
例えば、画像認識や自然言語処理など、人間の感覚に近い判断が必要な場面では、従来の機械学習モデルでは十分な精度を達成できないことがあります。
また、特徴量設計の難しさも落とし穴となります。
データのどの特徴に着目すべきかを人間が適切に設計しなければならないため、ドメイン知識と機械学習の知識の両方を持つ人材が必要になります。
適切な特徴量を設計できなければ、モデルの性能は大きく低下してしまいます。
さらに、新たな種類のデータやパターンに対する適応性の低さも課題です。
学習したパターンから大きく外れるデータに対しては対応が難しく、環境が大きく変化する状況下では再学習や再設計が必要になることがあります。
ディープラーニングが圧倒的に強い領域
ディープラーニングが特に威力を発揮する領域は明確です。
最も顕著なのは、複雑なパターン認識タスクにおける圧倒的な精度です。
画像認識、音声認識、自然言語処理など、従来のアルゴリズムでは対応が難しかった複雑な判断において、人間に匹敵する、あるいは人間を上回る精度を達成できることがあります。
また、特徴量の自動抽出能力も大きな強みです。
人間が気づかなかったデータ内の微妙なパターンも自動的に発見できるため、未知の関係性を見つける可能性が高まります。
これは、データから新たな知見を得たい探索的分析において特に価値があります。
さらに、マルチモーダル学習の可能性も注目すべき点です。
画像と文章、音声とテキストなど、異なる種類のデータを組み合わせて学習できる能力は、より豊かな情報処理を可能にします。
例えば、医療画像と患者データを組み合わせた診断支援などがこれに当たります。
ディープラーニング導入の現実的な障壁
しかし、ディープラーニングの導入には克服すべき障壁も多くあります。
最も大きな障壁は、大量のデータ要件です。
多くの場合、良好な結果を得るためには膨大な量の学習データが必要となり、データが少ない領域では過学習のリスクが高まります。
特に、ビジネスの新規領域や特殊な分野では、十分なデータ量を確保できないことがネックになりがちです。
次に、高い計算リソース要件も現実的な問題です。
学習には高性能なGPUやTPUなどの専用ハードウェアが必要であり、インフラ投資やクラウドコストが大幅に増加する可能性があります。
また、モデルの学習には数日から数週間かかることもあり、開発サイクルの長期化も課題となります。
加えて、専門知識を持つ人材の確保も難しさの一つです。
ディープラーニングの設計・実装・運用には高度な専門知識が必要であり、人材不足とコスト増加につながりがちです。
日本国内ではこの傾向が特に顕著であり、専門人材の確保が導入の大きなボトルネックとなっています。
業種・目的別の最適な選択方法

AI技術の導入は、業種や目的によって最適なアプローチが大きく異なります。
この章では、主要な業界での具体的な活用事例を紹介しながら、どのような状況でどちらの技術を選ぶべきかの指針を示します。
実際のビジネスシーンを想定した選択基準を解説していきましょう。
製造・小売・金融での機械学習活用法
製造業では、機械学習を活用した予知保全が広く普及しています。
センサーデータから機械の故障を予測することで、計画的なメンテナンスが可能になります。
この分野では、データ量が限られていることも多く、解釈可能性が重要視されるため、ランダムフォレストやサポートベクターマシンなどの従来型機械学習が適しています。
小売業においては、顧客セグメンテーションや需要予測に機械学習が活躍しています。
例えば、購買履歴から顧客をクラスタリングし、ターゲティングの精度を高めたり、過去の販売データから将来の需要を予測したりするケースが一般的です。
これらのタスクには、データ量が必ずしも膨大でなくても効果を発揮できる機械学習アルゴリズムが適しています。
金融分野では、与信判断やリスク評価に機械学習が広く採用されています。
特に、説明可能性が求められる規制環境下では、判断根拠を明示できる機械学習モデルが重宝されます。
具体的には、ロジスティック回帰や決定木ベースのアルゴリズムが、その判断プロセスの透明性から選ばれることが多いです。
医療・自動車・セキュリティ業界の成功事例
医療分野では、画像診断にディープラーニングが革命をもたらしています。
例えば、X線やMRI画像からがんを検出する技術は、画像の微細なパターンを認識できるCNN(畳み込みニューラルネットワーク)の登場により大きく進化しました。
人間の専門医と同等以上の精度で診断支援を行うモデルも出現しています。
自動車業界では、自動運転技術の核となる物体認識にディープラーニングが不可欠です。
カメラやLiDARからの入力を解析し、歩行者や他の車両、交通標識などをリアルタイムで認識する能力は、多層ニューラルネットワークが持つ高度なパターン認識力なしには実現できません。
セキュリティ分野では、顔認証システムや異常検知にディープラーニングが活用されています。
特に監視カメラ映像から不審な行動を検出するシステムは、複雑な動作パターンを学習できるディープラーニングの能力を活かした好例です。
また、サイバーセキュリティにおける異常通信検知なども、複雑なパターンを認識できるディープラーニングの得意分野になっています。
目的別で選ぶ:予測分析には機械学習、パターン認識にはディープラーニング
ビジネス目的に応じた技術選択も重要な視点です。
予測分析やデータマイニングの目的であれば、多くの場合、機械学習が効率的な選択となります。
例えば、売上予測、顧客離反予測、価格最適化などのタスクでは、データの関係性が比較的単純であることが多く、機械学習の方が開発効率やコスト面で優れています。
また、結果の解釈が容易であるため、ビジネス判断に直結させやすいという利点もあります。
一方、複雑なパターン認識が必要な場合はディープラーニングが適しています。
画像認識、音声認識、自然言語処理などの分野では、人間の感覚に近い判断が求められるため、多層ニューラルネットワークの力が必要です。
例えば、商品画像の自動分類、音声コマンドの認識、カスタマーレビューの感情分析などは、ディープラーニングの得意分野です。
具体的には、以下のような目的に応じた技術選択が一般的です。
- 数値予測(売上予測、価格予測など)→ 機械学習
- 分類問題(スパム検知、与信判断など)→ 比較的単純なものは機械学習
- 画像処理(物体検出、画像分類など)→ ディープラーニング
- 音声・言語処理(音声認識、翻訳など)→ ディープラーニング ・異常検知(不正検出、品質管理など)→ 用途に応じて使い分け
業種問わず使える:目標と予算に応じた段階的な技術導入ステップ
どの業種においても、AI技術を段階的に導入していくアプローチは効果的です。
以下のステップを参考にすることで、リスクを最小化しながら徐々に高度な技術へ移行することができます。
ステップ1:データ収集・整備フェーズ まずは必要なデータを収集し、品質を確保することが最初の課題です。
この段階では、機械学習のシンプルなモデルを用いた「クイックウィン」を狙うことがおすすめです。
例えば、基本的な統計分析や単純な予測モデルから始めることで、データの価値を検証できます。
ステップ2:機械学習の実践フェーズ データ基盤が整ったら、本格的な機械学習モデルの導入に着手します。
ランダムフォレストや勾配ブースティングなどの手法は、多くのビジネス課題で高い費用対効果を発揮します。
この段階で、AIの活用領域を徐々に拡大していきます。
ステップ3:ディープラーニング導入フェーズ 機械学習の限界に直面したタスクや、より高度な認識能力が必要な領域に、ディープラーニングを適用します。
初期投資は大きくなりますが、従来技術では解決できなかった問題へのブレークスルーが期待できます。
このような段階的アプローチにより、初期コストを抑えながら、組織のAI成熟度と共に技術レベルを高めていくことができます。
成功体験を積み重ねることで、より大規模なAI投資への土台を築くことができるでしょう。
AIエンジニアが教える技術選択の実践ノウハウ
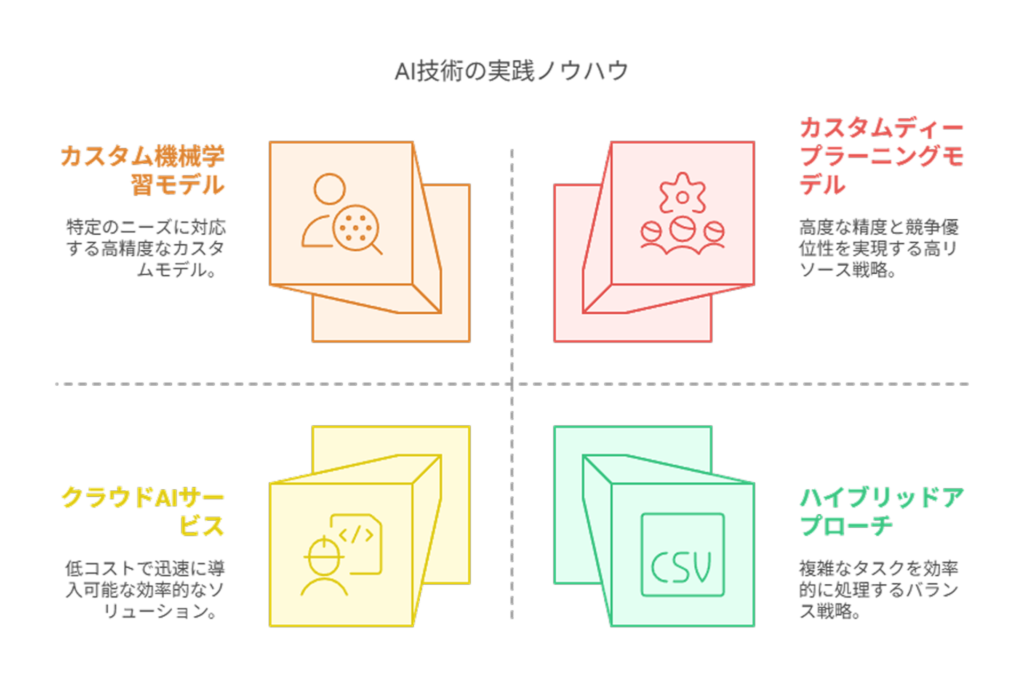
実際の現場では、機械学習とディープラーニングの技術選択をどのように行っているのでしょうか。
ここでは、AI開発の実務経験から得た具体的なノウハウを紹介します。
技術選択の判断基準から実装のポイントまで、実践的な知識を解説していきます。
プロジェクト要件から適切な学習モデルを選定するコツ
AI技術選択のスタート地点は、プロジェクト要件の明確化です。
以下の質問に回答していくことで、適切な技術選択の道筋が見えてきます。
まず、「何を予測・判断したいのか」を明確にします。
数値予測、分類、パターン認識、異常検知など、タスクの性質によって最適なアルゴリズムは異なります。
例えば、テキストデータを扱う場合でも、単純な分類なら機械学習(ナイーブベイズや SVM など)で十分ですが、文脈理解が必要なら BERT などのディープラーニングモデルが必要になります。
次に、「どのようなデータがどれくらいあるのか」を評価します。
データ量が少ない(数百〜数千件程度)場合は従来の機械学習が現実的です。
数万件以上の大量データがあり、かつ複雑なパターンを捉える必要がある場合にディープラーニングの検討が妥当になります。
また、「どの程度の精度が必要か」という点も重要です。
99%以上の高精度が求められる医療診断や自動運転などの分野では、ディープラーニングによる高度なモデルが必要になるケースが多いですが、80〜90%程度の精度で十分なマーケティング予測などでは、シンプルな機械学習モデルでコストパフォーマンスを重視する選択も合理的です。
最後に「説明可能性の要件」を確認します。
金融審査など説明責任が重視される領域では、判断根拠が明示できる機械学習モデルが適していることが多いです。
予算と期間に応じた現実的な手法の選び方
実務においては、理想的な技術と現実的な制約のバランスを取ることが重要です。
予算と期間の制約に応じた現実的な選択について考えてみましょう。
短期間・低予算プロジェクトでは、既存のクラウドAIサービスやオープンソースの機械学習ライブラリを活用するのが効率的です。
例えば、Google Cloud AIやAzure Cognitive Servicesなどのクラウドサービスは、API経由で高度な機能を低コストで利用できます。
また、scikit-learnなどのライブラリを使用すれば、少ないコーディング量でモデルを構築できます。
中期・中規模予算プロジェクトでは、カスタム機械学習モデルの開発が現実的な選択肢となります。
プロジェクト固有のデータに基づいたモデルチューニングにより、汎用APIより高い精度を実現できます。
この段階では、データサイエンティスト1〜2名と数ヶ月の開発期間を想定すると良いでしょう。
長期・高予算プロジェクトでは、カスタムディープラーニングモデルの開発が選択肢に入ります。
専門チームの編成、計算リソースの確保、大量のデータ収集など、初期投資は大きくなりますが、他社が真似できない競争優位性を築ける可能性があります。
ただし、6ヶ月以上の開発期間と、相応の人材・設備投資が必要になることを理解しておく必要があります。
現実的なアプローチとしては、小規模な「プルーフオブコンセプト(PoC)」から始め、成果を確認しながら段階的に投資を拡大していくことが賢明です。
ハイブリッドアプローチ:両技術の強みを組み合わせる方法
実務では、機械学習とディープラーニングを対立的に捉えるのではなく、それぞれの強みを活かしたハイブリッドアプローチが効果的なケースも多くあります。
これにより、精度と効率性の両立が可能になります。
最も一般的なハイブリッドアプローチは、「特徴抽出にディープラーニング、最終判断に機械学習」という組み合わせです。
例えば、画像から特徴を抽出するためにCNNを使い、その特徴を入力として機械学習モデル(SVMやランダムフォレストなど)で分類を行うという方法があります。
これにより、ディープラーニングの優れた特徴抽出能力と、機械学習の解釈可能性を両立できます。
また、「前処理・フィルタリングに機械学習、詳細分析にディープラーニング」という階層的アプローチも効果的です。
例えば、大量のデータから異常値や関心対象をまず機械学習で絞り込み、その対象データだけをディープラーニングで詳細分析するという方法です。
これにより、計算コストを抑えながら、必要な部分で高度な分析を行うことができます。
産業応用では、「ルールベース+機械学習+ディープラーニング」の三層構造を採用するケースもあります。
基本的な判断はルールベース、中程度の複雑さは機械学習、高度なパターン認識はディープラーニングと、タスクの複雑さに応じて使い分ける設計です。
この方法は特に、ミッションクリティカルなシステムで信頼性と先進性のバランスを取る際に有効です。
失敗しないためのPoC(概念実証)設計のポイント
AI技術の導入においては、本格的な開発の前にPoC(概念実証)を行うことが重要です。
多くの企業がAIプロジェクトで失敗する原因は、PoCの設計ミスにあります。ここでは、成功率を高めるためのポイントを紹介します。
まず、「実証したい仮説を明確化する」ことが最重要です。
「AIを使えば何か良いことがあるはず」という漠然とした期待ではなく、「この特定の問題に対して、どの程度の精度で解決できるか」といった具体的な仮説を立てましょう。
例えば「過去の購買データから、次月の購入確率を70%以上の精度で予測できるか」などの検証可能な形にします。
次に、「小さく始めて素早く検証する」姿勢が重要です。
複雑なディープラーニングでいきなり始めるのではなく、まずは単純な機械学習モデルでベースラインを作り、そこから段階的に複雑なモデルへと発展させていくのが賢明です。
また、データの一部(例えば10%)だけを使った予備実験から始めることも、検証サイクルを速めるコツです。
さらに、「ビジネス指標との紐付け」も不可欠です。技術的な評価指標(精度や再現率など)だけでなく、「このAIによってコストがいくら削減できるか」「売上がどれだけ向上するか」といったビジネス価値を試算することで、経営層の理解と支援を得やすくなります。
最後に、「実運用を見据えたPoC設計」を意識しましょう。
しばしば理想的な条件下でのみ機能するPoCが、実運用では失敗するケースがあります。
実際のデータ品質問題や運用フローを考慮したうえで実験を設計することが、本番での成功確率を高める鍵となります。
まとめ:機械学習とディープラーニングの使い分けと将来展望
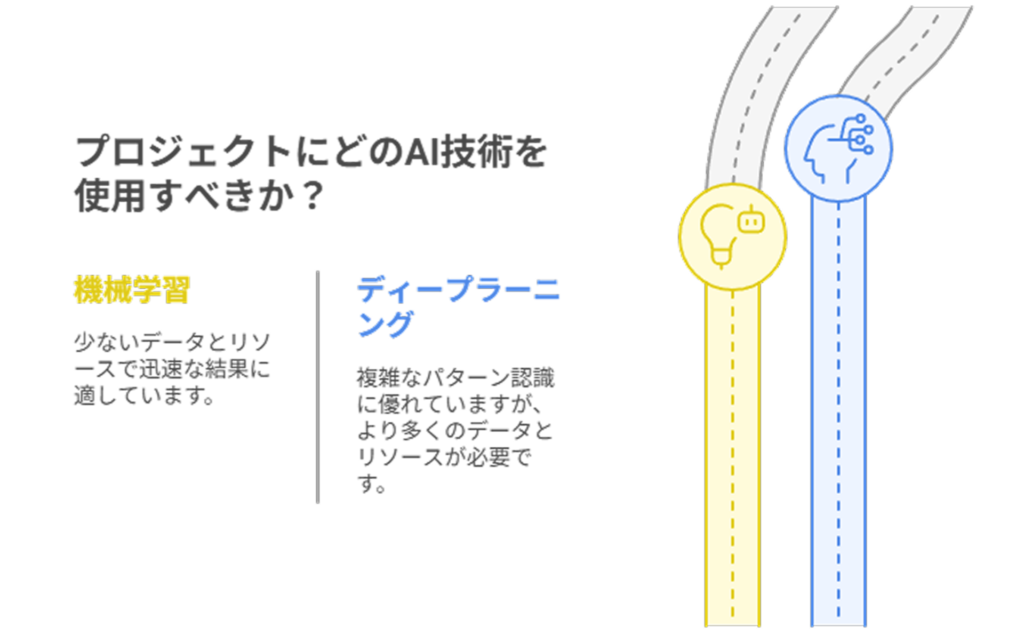
機械学習とディープラーニングは、AIという大きな枠組みの中でそれぞれ特性の異なる技術です。
機械学習は少ないデータでも短期間・低コストで成果を出せる一方、ディープラーニングは複雑なパターン認識に優れていますが、大量のデータと計算リソースを必要とします。
技術選択は、課題の性質、データ量、予算、期間などを総合的に考慮して行うべきです。
単純な予測には機械学習、画像・音声認識には主にディープラーニングが適しています。段階的な導入やハイブリッドアプローチも効果的です。
将来的には両技術の境界は曖昧になっていくでしょうが、重要なのは技術そのものよりも、それがもたらすビジネス成果です。
【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIを業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


