
ファインチューニング完全攻略!事前学習済みAIを自社用にカスタマイズする極意
この記事でわかること
- ファインチューニングの仕組みと意義
- 他の手法との違いや使い分け方
- ファインチューニング用データセットの準備方法
- ChatGPTをファインチューニングする具体的な手順
- 業界別のファインチューニング活用事例
- ファインチューニングを成功させるためのポイントと注意点

ファインチューニングは、事前学習済みのAIモデルを自社のタスクに適応させる強力な手法です。本記事では、ファインチューニングの基本概念から実践的な手法、活用事例、留意点まで、網羅的に解説します。ファインチューニングを活用することで、中小企業でも高精度のAIを手軽に構築できるようになります。自社のAI活用を加速するヒントが満載です。

目次
ファインチューニングとは?機械学習モデルの転移学習による最適化
ファインチューニングは、AI開発の現場で重要性を増している技術です。この手法は、すでに大量のデータで訓練されたモデルを取り、特定のタスクやデータセットに合わせて微調整することで、追加学習を行います。
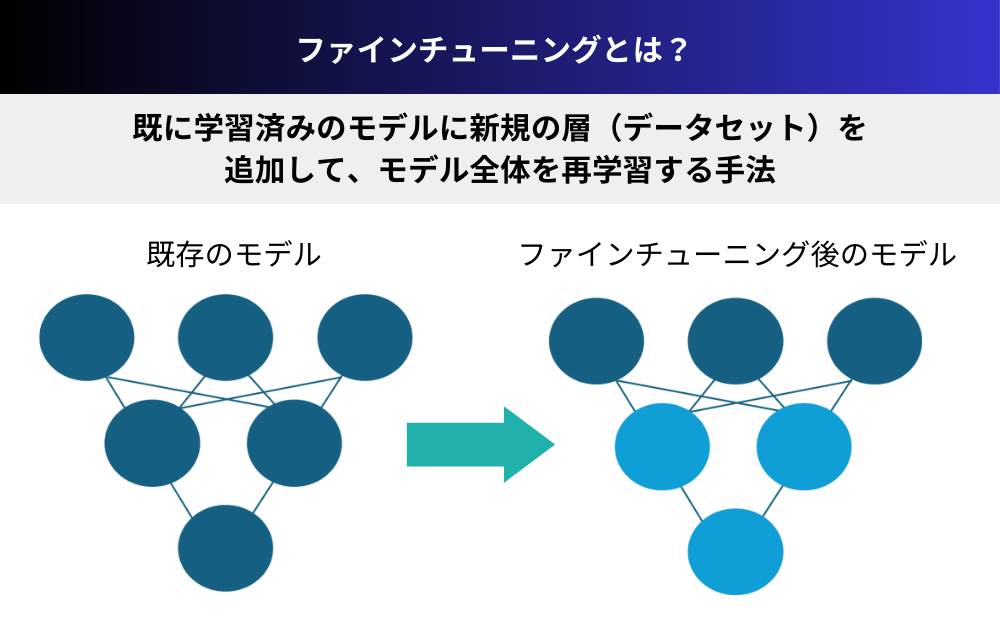
事前学習済みモデルを特定タスクに適応させる仕組み
ファインチューニングとは、事前学習済みの機械学習モデルを特定の目的やドメインに合わせて微調整するプロセスです。つまり、大規模なデータセットで訓練された汎用的なモデルを、自社の業務に関連する限定的なデータで再学習させ、パフォーマンスを最適化させるのです。
この仕組みの肝となるのが転移学習という考え方です。転移学習では、あるタスクで学習した知識やスキルを別の関連タスクに応用します。例えば、大量の一般的な画像で学習した画像認識モデルを、自社製品の不良品検知用に追加学習させるといった具合です。この時、最初から学習し直す必要はなく、基本的な特徴抽出能力はそのまま活かしつつ、出力層の調整によってモデルを自社の課題に適応させるのです。
少量データでも高精度のAIを実現するファインチューニングの意義

ファインチューニングのメリットは、限られたデータやリソースでも高性能なAIモデルを構築できる点にあります。巨大なデータセットや計算資源を用意できる大企業や研究機関と違い、中小企業にとってAI開発のハードルは高いものです。しかしファインチューニングにより、オープンソースの事前学習済みモデルを自社のニーズに合わせて手軽にカスタマイズできます。
加えて、データ収集が難しい特殊分野や、データ量自体が少ないユースケースでも、ファインチューニングは威力を発揮します。わずかな追加データで、汎用モデルから高精度の特化型モデルへと進化させられるのです。AIの民主化とも言えるこの手法は、大企業だけでなく、あらゆる業界のプレイヤーにとって、ゲームチェンジャーとなるでしょう。
ファインチューニングと他の手法の違いを理解する

ファインチューニングは、転移学習やRAGといった他の機械学習手法としばしば比較されます。これらの手法もモデルの性能を向上させる目的で使用されますが、適用の仕方や目的において異なる点があります。
転移学習の一種としてのファインチューニング
ファインチューニングは転移学習の一種であり、他の代表的な手法としては特徴抽出や領域適応があります。特徴抽出は、事前学習済みモデルから特徴量を抽出し、その上で新しい分類器を学習させる手法です。対して、ファインチューニングでは、モデルの一部または全体を再学習させて、直接的にパフォーマンスを改善させます。
領域適応も、ソースドメインで学習したモデルをターゲットドメインに適用する点ではファインチューニングと類似しています。ただし、ファインチューニングがモデルのパラメータ調整を主軸とするのに対し、領域適応ではドメイン間の分布の違いを吸収することに主眼が置かれます。
ファインチューニングとRAGの違い
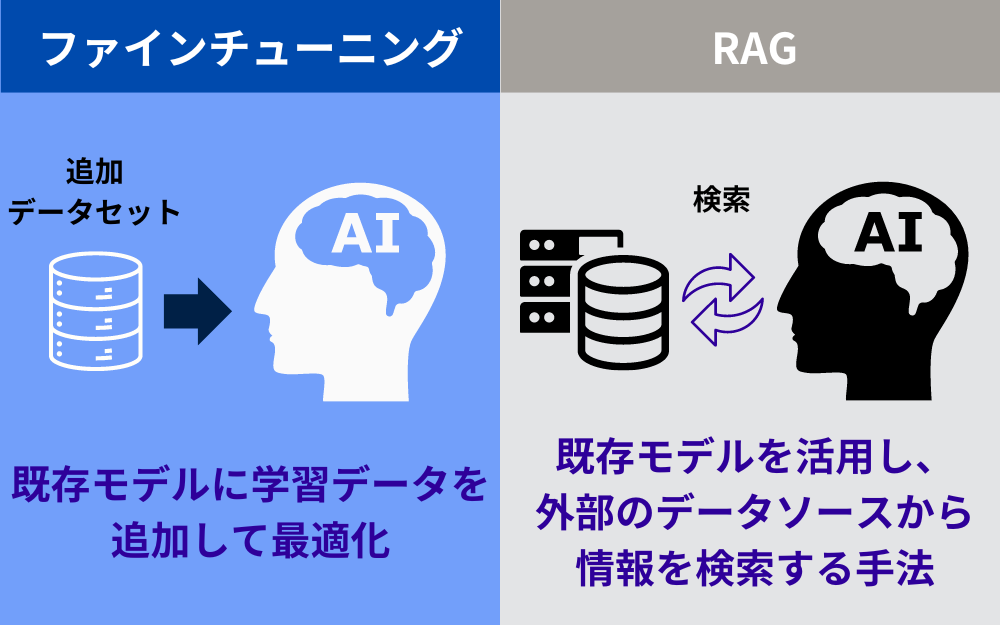
ファインチューニングと混同されがちな別の手法に、RAG(Retrieval-Augmented Generation)があります。RAGは大規模言語モデルと情報検索を組み合わせた生成モデルで、入力に関連する情報を外部ナレッジベースから取得し、それを基に最適な応答を生成します。
RAGとファインチューニングの決定的な違いは、RAGがモデルの内部パラメータを調整するのではなく、外部知識を直接活用する点です。つまり、ファインチューニングが事前学習済みモデルを特定ドメインに適応させるのに対し、RAGは汎用的な生成能力はそのままに、情報検索連携で知識ベースを拡張するのです。用途や目的に応じて、使い分けが必要な手法だと言えるでしょう。
ファインチューニングのメリット3点
ファインチューニングは、特にデータが限られている場合や、開発リソースが制約されている状況で、AIモデルの運用を可能にする重要な手段です。実施するメリットとして以下の3点があります。

1.学習データが少なくても高精度なAIモデルを構築できる
ファインチューニングの最大のメリットは、大規模なデータセットがなくても、高性能なAIモデルを開発できる点です。事前学習済みモデルが持つ豊富な知識や特徴抽出能力を活用することで、限られた追加データでもモデルを特定ドメインに適応させられます。
特に、医療や金融など、データ収集に制約のある分野や、そもそもデータ量が少ないニッチな業務では、ゼロからモデルを学習させるのは非現実的です。そうした状況でこそ、ファインチューニングの出番と言えるでしょう。少ないデータを最大限に活用し、実用に耐えうるAIシステムを短期間で開発できるのです。
2.開発コストと期間を大幅に削減できる
ファインチューニングのもう一つの大きなメリットが、開発コストと期間の大幅な削減です。事前学習済みモデルをベースにすれば、ゼロからモデル構築をする必要がなくなります。つまり、データ収集や特徴設計、モデルのトレーニングなどに膨大な時間とコストをかける必要がないのです。
加えて、ファインチューニング自体の所要時間も短く、少ない計算リソースで実行できます。これにより、AIプロジェクトの敷居が大きく下がり、中小企業でも気軽に取り組めるようになります。また、大企業にとっても、新サービスの立ち上げやPoC(概念実証)を迅速かつ安価に行えるメリットは計り知れません。
3.モデルの汎用性が向上し、様々なタスクに応用できる
ファインチューニングのメリットは、単に精度向上やコスト削減だけにとどまりません。この手法を活用することで、AIモデルの汎用性や柔軟性も大きく向上するのです。事前学習済みモデルは、大規模で多様なデータから得た豊富な知識を内包しています。そのため、ファインチューニングを経たモデルは、本来の用途以外にも幅広く応用できる可能性を秘めているのです。
例えば、文書分類用にファインチューニングしたモデルが、感情分析やキーワード抽出にも使えたり、画像認識モデルが異常検知にも転用できたりと、用途の幅が格段に広がります。つまり、一度ファインチューニングしたモデルが、社内の様々な課題解決に役立つ可能性があるのです。AIの活用アイデアが広がれば、DXのスピードアップにもつながるでしょう。
ファインチューニングのデメリット2点
ファインチューニングは多くのメリットをもたらしますが、実施する際には、以下の2つの主なデメリットがあります。

1.元のモデルのバイアスが引き継がれる可能性がある
ファインチューニングの注意点として、事前学習済みモデルが持つバイアスが、そのまま引き継がれる可能性があるという点が挙げられます。大規模データで学習されたモデルは、人種、性別、年齢などに関する社会的偏見を内包している可能性があります。そのようなモデルをファインチューニングしても、バイアスまでは除去できないケースが少なくありません。
特に、公平性が求められる業務(採用選考、融資審査、医療診断など)にAIを導入する際は、モデルのバイアスに細心の注意を払う必要があります。元となるモデルの選定や検証にあたっては、倫理的な観点からの評価が欠かせません。加えて、自社データによるファインチューニング後も、アウトプットの公平性をチェックする体制づくりが肝要でしょう。
2.事前学習済みモデルへの依存が高くなる
ファインチューニングのもう一つの留意点は、事前学習済みモデルへの依存度が高くなるという点です。特に、自然言語処理や画像認識など、大規模モデルが強力な分野では、自前でモデル開発することが難しくなってきています。つまり、ファインチューニングを前提とすると、オープンソースや他社製のモデルに頼らざるを得なくなるのです。
モデルの入手可能性やライセンス、将来的なサポートなどを考えると、特定のモデルに依存するリスクは小さくありません。また、事前学習済みモデルの構造が「ブラックボックス」であるため、不具合やエラーへの対処も難しくなります。ビジネスの根幹にかかわるAIであれば、モデル自体をコントロールできることが望ましいでしょう。ファインチューニングと自社開発のバランスを取ることが肝要です。
ファインチューニング用データセット準備の3ステップ
ファインチューニング用のデータセットを準備する際には、以下のようなステップを踏む必要があります。

ステップ1:タスクの明確化と必要なデータの収集
ファインチューニング用のデータセットを準備する際、まず行うべきはタスクを明確に定義することです。ファインチューニングの目的、つまり、事前学習済みモデルにどのような機能を追加したいのかを具体的に定めます。文書分類、質問応答、物体検出など、タスクの内容に応じてデータの種類や形式が異なります。
タスクが定まれば、次はデータ収集です。モデルの性能を左右するのがデータの質と量であることを意識しましょう。ファインチューニングとはいえ、タスクに関連するデータが少なすぎては精度向上は見込めません。社内データだけでなく、公開データセットやクラウドソーシングの活用も検討すべきでしょう。ただし、データの取得にあたっては、知的財産権や個人情報の取り扱いに十分留意が必要です。
ステップ2:データの前処理とクリーニングのコツ
データを集めただけでは、まだファインチューニングには使えません。生のデータは形式やフォーマットが不統一で、ノイズやエラーを含んでいるのが常だからです。そこで、モデルに食わせる前に、データの前処理やクリーニングを行う必要があります。
前処理ステップでは、データのフォーマット変換や正規化、スケーリングなどを行います。例えば、テキストデータならばトークン化や句読点の除去、数値データなら標準化などの操作が必要です。画像の場合は、サイズの統一やRGBとグレースケールの変換など、用途に応じた処理を施します。
クリーニングでは、欠損値、異常値、重複データなどのノイズを取り除きます。クリーニング手法はタスクやデータの性質によって異なりますが、基本は統計的な外れ値検出と、業務知識に基づくルールの組み合わせになります。自然言語処理では、スペルミスの修正やストップワードの除去なども重要です。
前処理とクリーニングのポイントは、徹底した自動化を進めることです。手作業では膨大な時間がかかるうえ、ミスも発生しがちです。Pythonなどのプログラミング言語を駆使し、データパイプラインを構築しましょう。
加えて、再現性の担保も肝心です。前処理やクリーニングのロジックを明確にし、バージョン管理することが重要です。データに変更があった場合も、同じ処理を適用できる環境を整えるのです。
また、前処理とクリーニングには、ドメインの専門知識が欠かせません。例えば、医療データの場合、臨床医の監修が不可欠でしょう。法律や金融などの分野でも、専門家の知見を反映させる必要があります。
データサイエンティストとドメインエキスパートが協力し、ファインチューニングに最適なデータを整備する。それが、プロジェクト成功のカギを握ると言えるでしょう。品質の高いデータがあってこそ、ファインチューニングの真価が発揮されるのです。
ステップ3:訓練・検証・テストセットへのデータ分割の基準
データの前処理とクリーニングが終われば、いよいよファインチューニングにかかれます。しかし、その前に欠かせないのがデータセットの分割です。機械学習モデルの性能を正しく評価し、過学習を防ぐためには、データを訓練用、検証用、テスト用に適切に分ける必要があります。
訓練データはモデルのパラメータ調整に、検証データはハイパーパラメータのチューニングに使います。テストデータは仕上がったモデルの性能を評価するために用います。分割の比率は、データ量や用途によって異なりますが、一般的には訓練:検証:テスト=6:2:2や7:1:2などが採用されます。
ポイントは、データの偏りを避けることです。例えば、時系列データなら日付順に分割するのではなく、ランダムサンプリングが望ましいでしょう。また、データの分布が偏っている場合は、層化サンプリングも効果的です。ファインチューニングを成功させるカギは、モデルに多様で汎化性能の高いデータを学習させることなのです。
ファインチューニングの実践: 事前学習済みモデルのカスタマイズ手法
いよいよファインチューニングの実践フェーズです。事前学習済みモデルをカスタマイズするための手法を、順を追って解説していきましょう。

ドメイン適応のためのモデルアーキテクチャの選定
いよいよファインチューニングの実践フェーズです。まずは、事前学習済みモデルのアーキテクチャ選定から始めましょう。モデルは用途に合ったものを選ぶ必要があります。例えば、自然言語処理ではBERT、GPT、XLNetなどの大規模言語モデルが、画像認識ではResNetやEfficientNetなどの畳み込みニューラルネットワークが使われます。
選定ポイントは、モデルの構造がタスクにマッチしているか、事前学習に使われたデータが自社のデータと親和性があるかです。また、モデルサイズとパフォーマンスのトレードオフ、推論速度なども考慮しましょう。できれば複数のモデルを比較検討し、最適なものを見つけ出すことが理想です。
もう一つの選択肢は、モデルアーキテクチャの一部を変更することです。例えば、出力層を置き換えたり、ドメイン固有の特徴量を抽出する層を追加したりします。ただし、この手法はファインチューニングの枠を超えてモデル設計に踏み込むことになるので、AIエンジニアとの連携が欠かせません。
ハイパーパラメータの調整とその影響
事前学習済みモデルを自社データで再学習させる際、学習率、バッチサイズ、エポック数などのハイパーパラメータ調整が重要になります。特に学習率は、事前学習済みの重みをどの程度更新するかを決める重要なファクターです。学習率が高すぎれば既存の知識が失われ、低すぎれば学習が進まないというジレンマがあります。
ファインチューニングでは、事前学習時より学習率を下げるのが一般的です。1/10程度に設定し、徐々に下げていくファインチューニングスケジュールがよく採用されます。バッチサイズは、利用可能なメモリ量に応じて設定します。エポック数は、検証データの損失が下がらなくなるまで回すのが基本ですが、過学習に注意が必要です。
ハイパーパラメータ探索の効率化には、グリッドサーチやランダムサーチなどの自動最適化手法が役立ちます。ただし、ブラックボックス最適化では、パラメータの意味を理解しにくくなるので、注意深いモニタリングが欠かせません。試行錯誤を重ねながら、タスクに最適なファインチューニングの設定を見つけていきましょう。
特徴抽出層の凍結と再学習の使い分け
ファインチューニングのテクニックとして、特徴抽出層の凍結と再学習の使い分けがあります。事前学習済みモデルは、汎用的な特徴抽出能力を持つ層(encoder)と、タスク固有の出力を担う層(head)から構成されます。ファインチューニングでは、モデル全体を再学習させるのが基本ですが、特徴抽出層を凍結し、出力層だけを再学習させる手法もあります。
特徴抽出層の凍結は、事前学習で獲得した汎用的な知識を保持しつつ、出力層だけをタスクに適応させるものです。これにより、学習の高速化と過学習リスクの低減が期待できます。ただし、ドメイン固有の特徴を抽出できない可能性や、headの表現力不足といった課題もあります。
一方、特徴抽出層も含めた再学習は、よりドメインに特化した特徴量を獲得できるメリットがあります。ただし、大規模モデルの場合は著しい学習コストがかかるのが難点です。使い分けのポイントは、タスクとドメインの関連度、データ量、リソースの制約などです。両者のトレードオフを見極め、最適なファインチューニング戦略を練ることが肝要でしょう。
ChatGPTでファインチューニングするための5ステップ
ChatGPTをはじめとするOpenAIの言語モデルは、ファインチューニングによって自社のタスクに特化させることができます。ここでは、ChatGPTをファインチューニングするための5つのステップを詳しく説明します。
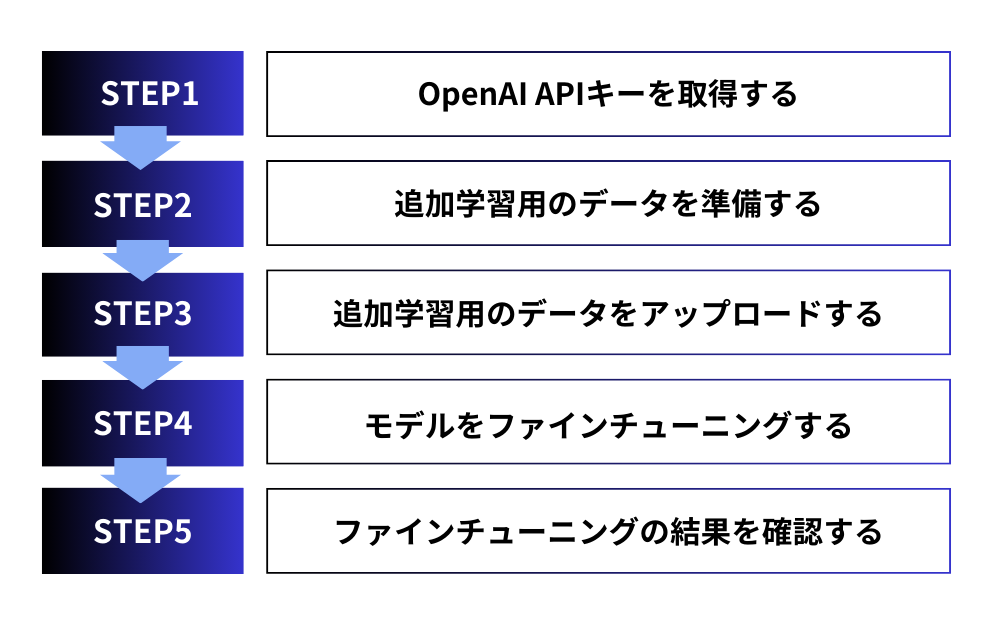
ステップ1:OpenAI APIキーを取得する
ChatGPTなどのOpenAIモデルをファインチューニングするには、まずOpenAI APIへの登録が必須です。OpenAIのWebサイトでアカウントを作成し、APIキーを取得します。APIキーは、モデル利用やデータアップロード、ファインチューニング実行の認証に使うので、厳重に管理しましょう。
APIの利用には料金がかかることにも注意が必要です。無料利用枠はあるものの、大規模なファインチューニングには一定のコストがかかります。ビジネス利用の場合は、課金体系を確認し、予算との兼ね合いを考えましょう。
ステップ2:追加学習用のデータを準備する
ChatGPTのファインチューニングには、モデルに追加学習させたいQ&Aペアや文章を大量に用意する必要があります。データの質と量が、ファインチューニングの成否を分けることを肝に銘じましょう。自社のFAQや過去の問い合わせ履歴、ドキュメントなどが、データソースとして活用できるはずです。
データの形式は、JSONLというJSON Lines形式が推奨されています。各行に1つのデータサンプルを記述し、プロンプトと応答のペアを定義します。詳細は公式ドキュメントを参照しつつ、確実にOpenAIのフォーマットに合わせることが大切です。
また、データの精査やクリーニングも重要なステップです。誤りや不適切な表現、機密情報などを含むデータは、除外するようにしましょう。ファインチューニング後のモデル出力に悪影響を及ぼしかねないためです。データの品質管理には細心の注意を払う必要があります。
ステップ3:追加学習用のデータをアップロードする
データセットが準備できたら、OpenAI APIを通じてアップロードします。具体的には、openai CLIツールを使ってデータをOpenAIのサーバーに転送するのが一般的です。アップロードにはOpenAI APIキーによる認証が必要です。
アップロードしたデータは、OpenAIのプライバシーとセキュリティ基準に則って厳重に管理されます。ただし、データの機密性が極めて高い場合は、自社サーバーでのファインチューニングも検討すべきでしょう。
ステップ4:モデルをファインチューニングする
データのアップロードが完了したら、いよいよファインチューニングを実行します。OpenAI APIのファインチューニングエンドポイントに、ベースとなるモデルとデータセットを指定してリクエストを送信します。ベースモデルは、用途に応じてgpt-3.5-turbo、text-davinci-003などを選択します。
ファインチューニングのパラメータ(エポック数、バッチサイズ、学習率など)も、APIリクエストで指定できます。最適なパラメータ設定は試行錯誤が必要ですが、OpenAIの推奨値を参考にするとよいでしょう。
ファインチューニングのジョブは、OpenAIのサーバー上で非同期に実行されます。ジョブの進捗状況や結果は、APIを通じて随時確認できます。ファインチューニング完了までには、データ量やモデルサイズに応じて数時間から数日かかることもあるので、計画的に実行しましょう。
ステップ5:ファインチューニングの結果を確認する
ファインチューニングが完了すると、カスタマイズされたモデルが利用可能になります。APIを通じて、ファインチューニング済みモデルの性能を確認しましょう。テストデータに対する精度や、実際のタスクでの動作チェックが必要です。
もし期待通りの結果が得られない場合は、データの追加や修正、ハイパーパラメータの調整などを行い、再度ファインチューニングを実行します。満足のいく性能が得られるまで、改善を繰り返すのがポイントです。
一方、ファインチューニング済みモデルが実用レベルに達したら、APIを通じて本番環境から利用できます。自社のアプリケーションやサービスに組み込んで、ChatGPTの能力を存分に活用しましょう。ただし、APIの利用量に応じた課金には十分注意が必要です。
業界別に見るファインチューニングの活用事例
ファインチューニングは、様々な業界で実践され、AIの活用を促進しています。ここでは、自然言語処理、画像認識、レコメンデーションの3つの分野を取り上げ、ファインチューニングの活用事例を紹介します。

自然言語処理: 感情分析やテキスト要約モデルの高度化
自然言語処理の分野では、ファインチューニングが大きな威力を発揮しています。汎用的な言語モデルを土台に、特定の業務やドメインに特化した高精度のモデルが続々と生み出されているのです。
例えば、金融機関では、ニュース記事やSNS投稿の感情分析に、ファインチューニングされたモデルが活用されています。株価予測や市場分析の精度向上につながるため、AIへの投資が活発化しています。
また、法律や医療など専門性の高い分野でも、ファインチューニングによるテキスト要約モデルの高度化が進んでいます。膨大な判例や論文を要約し、知見を集約することで、専門家の意思決定を支援するAIアシスタントとして期待されているのです。
画像認識: 医療画像診断モデルの性能向上
ファインチューニングは、画像認識の分野でも大きなインパクトを与えています。中でも注目を集めるのが、医療画像診断への応用です。がんや疾患の早期発見に向けて、ファインチューニングされた画像認識モデルが活躍しているのです。
例えば、肺がんのCT画像診断では、ファインチューニングによって感度と特異度が大幅に改善されたという研究結果があります。一般的な画像認識モデルを、大量の肺CT画像で追加学習させることで、微小な病変も見逃さず検出できるようになったのです。
同様の取り組みは、眼底画像からの糖尿病性網膜症の診断や、皮膚がんの画像診断などでも進められています。エッジケースが多い医用画像こそ、ファインチューニングの価値を発揮できる領域だと言えるでしょう。
レコメンデーション: ユーザー行動データを活用した推薦精度の改善

EC(電子商取引)サイトやOTT(動画配信)サービスでは、ユーザーへのレコメンデーション(商品や動画のおすすめ)が重要な機能として定着しています。そのレコメンデーション品質の向上にも、ファインチューニングが一役買っています。
例えば、大手ECサイトでは、ユーザーの閲覧・購買履歴を活用し、商品推薦モデルのファインチューニングを行っています。サイト全体の売上アップにつながるため、レコメンデーションAIへの投資を惜しまないのです。
動画配信サービスでも、視聴履歴データを使ったファインチューニングが盛んです。ユーザーの嗜好にマッチした動画をレコメンドすることで、顧客満足度とエンゲージメント向上を狙っています。ファインチューニングの賜物と言えるでしょう。
金融機関でも、ファインチューニングを活用したレコメンデーションの取り組みが進んでいます。顧客の取引履歴や資産状況に基づいて、最適な金融商品を提案するモデルの開発が活発化しているのです。AIによるパーソナライズされた金融サービスの実現に向けて、ファインチューニングへの期待が高まっています。
ファインチューニングを成功させるための留意点
ファインチューニングを成功させるためには、いくつかの重要な留意点があります。ここでは、計算リソースの確保とコスト管理、データ品質とモデルの汎化性能のトレードオフ、ドメイン知識を活かしたモデル選定と評価の3つの観点から、ファインチューニングを成功に導くためのポイントを解説します。
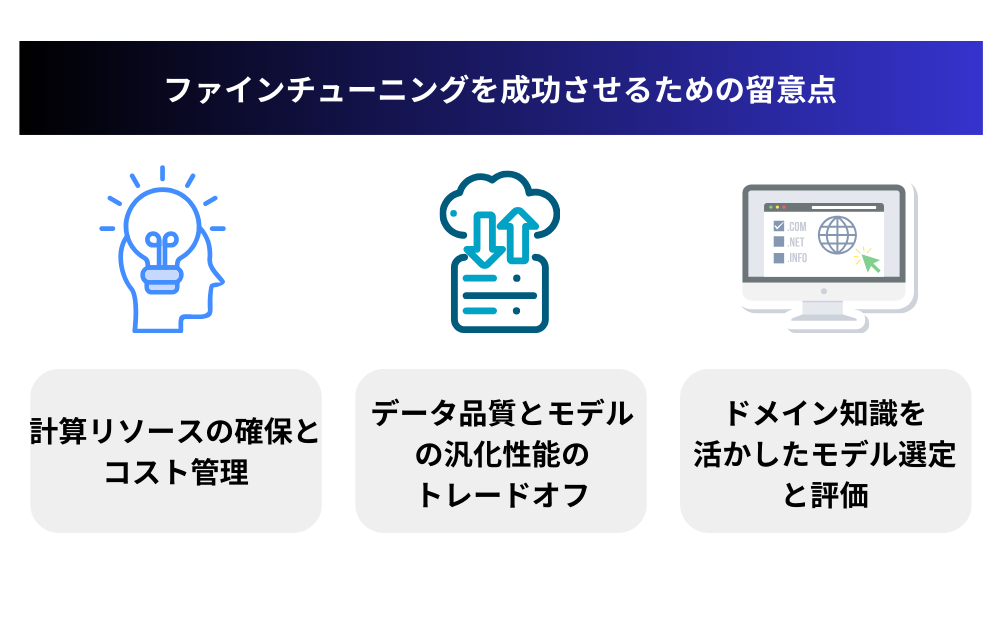
計算リソースの確保とコスト管理
ファインチューニングを成功させるためには、十分な計算リソースの確保が不可欠です。特に、大規模な事前学習済みモデルを使う場合、GPUやTPUなどの高性能なハードウェアが必要になります。クラウドサービスを活用するにしても、利用料金はかなりの額になるでしょう。
したがって、ファインチューニングプロジェクトを始める前に、必要な計算リソースを見積もり、予算を確保することが肝要です。また、開発チームには、機械学習のワークフローに詳しいエンジニアやインフラ担当者の参画が望まれます。
コスト管理の面では、ファインチューニングの効率化が鍵を握ります。つまり、できるだけ少ない計算量で最大の効果を出すことが求められるのです。そのためには、データやモデルの選定、ハイパーパラメータの最適化など、様々な面での工夫が必要不可欠です。
データ品質とモデルの汎化性能のトレードオフ
ファインチューニングで高い精度を出すには、学習データの品質が重要な要素となります。つまり、モデルにできるだけ多くのタスク固有の情報を与えることが望ましいのです。しかし、ドメイン特化が過ぎると、モデルの汎化性能が損なわれる危険性もあります。
例えば、自社の顧客データだけでファインチューニングしたモデルは、社内の業務には最適でも、他社や新規顧客への適用は難しいかもしれません。モデルの適用範囲を広げるには、様々な状況をカバーする多様なデータが必要となるでしょう。
したがって、ファインチューニングではデータ品質と汎化性能のバランスを取ることが肝要です。プロジェクトの目的に応じて、学習データの種類や量、前処理方法などを適切に選択しなければなりません。専門家の知見を結集し、戦略的にファインチューニングを進めることが成功への近道となります。
ドメイン知識を活かしたモデル選定と評価
ファインチューニングの成否は、事前学習済みモデルの選択にも大きく左右されます。汎用的なモデルをベースにするにしても、タスクやドメインとの親和性を見極める必要があります。単に高精度というだけでなく、推論速度や計算コストなども考慮に入れるべきでしょう。
モデル選定には、機械学習の知識だけでなく、ドメインの専門性も求められます。例えば、医療分野でのファインチューニングなら、医師や医学研究者の知見が欠かせません。法律や金融など、他の専門分野でも同様でしょう。AI技術者とドメインエキスパートが協力し、最適なモデルを見出すことが理想です。
また、ファインチューニング済みモデルの評価も、ドメイン知識抜きには語れません。精度や速度といった機械学習の指標だけでなく、業務上の有用性や倫理的な側面まで考慮する必要があります。modelhubのような評価プラットフォームの活用も検討に値するでしょう。
要は、ファインチューニングをブラックボックス化せず、ドメインの文脈でしっかりと捉えることが肝要だということです。AI技術とビジネスの両面から、戦略的にプロジェクトを推進する姿勢が何より大切だと言えるでしょう。
まとめ: ファインチューニングで自社にカスタマイズされたAIモデルを活用しよう

本記事では、ファインチューニングの概要から実践的な手法、活用事例、留意点まで、幅広く解説してきました。最後に、ファインチューニングの重要性と課題を再確認し、自社のAI活用を加速するためのアクションプランを提案します。
ファインチューニングの重要性と課題の再確認
ファインチューニングは、事前学習済みモデルを自社のタスクやデータに適応させるための強力な手法です。転移学習の一種であるファインチューニングを活用することで、少量のデータや限られたリソースでも、高精度のAIモデルを構築できます。
自然言語処理や画像認識、レコメンデーションなど、様々な分野でファインチューニングの事例が報告されており、AIの民主化を後押ししています。中小企業や専門分野の組織にとって、ファインチューニングは、AI活用の敷居を大きく下げるものと言えるでしょう。
その一方で、ファインチューニングにはいくつかの課題もあります。事前学習済みモデルのバイアスの継承や、モデルへの依存リスクには十分な注意が必要です。また、計算リソースの確保やデータ品質の管理、ドメイン知識の活用など、プロジェクト運営には高度なスキルが求められます。
これらの課題を克服し、ファインチューニングを成功に導くには、技術面での工夫だけでなく、組織全体でAIに向き合う姿勢が欠かせません。経営層から現場まで、AIリテラシーを高め、データドリブンな意思決定を実践することが何より重要だと言えるでしょう。
自社のAI活用を加速するためのアクションプラン
最後に、ファインチューニングを起点に、自社のAI活用を加速するためのアクションプランを提案します。
AI人材の育成と確保
- 社内でのAI教育プログラムの実施
- 機械学習エンジニアやデータサイエンティストの採用
- 外部の専門家やコンサルタントとの協業
データ基盤の整備
- 社内データの棚卸しと統合
- データガバナンスの確立
- クラウドの活用などデータ基盤の刷新
ファインチューニングのPoCプロジェクト
- 自社の業務に適したタスクの選定
- 小規模なデータでファインチューニングを試行
- 成果の検証と課題の洗い出し
本格的なファインチューニングプロジェクトの立ち上げ
- 全社的なAI戦略の策定
- ファインチューニング基盤の構築
- モデルの性能検証と業務適用
AIを活用した新サービス・新商品の開発
- ファインチューニング済みモデルの応用可能性の探索
- 事業部門と連携した企画立案
- MVPの開発と市場投入
もちろん、これらのアクションプランは一般論であり、自社の状況に合わせたカスタマイズが必要です。しかし、重要なのは、ファインチューニングをきっかけに、AIを自社の競争力の源泉として位置づけることです。
経営層のコミットメントを得て、全社を挙げてAIに取り組む体制を整えましょう。さまざまな課題はありますが、ファインチューニングをテコに、AI活用の一歩を踏み出すことが肝要です。まずは小さく始めて、着実にAIの成果を積み重ねていく。そうした地道な努力の先に、AIによる企業変革の未来が拓けるはずです。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIをマーケティング業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


