
文字起こしAI「Whisper」の使い方や無料で使う方法を解説
この記事でわかること
- 文字起こしAI「Whisper」とは
- Whisperの5つのモデルを解説
- Whisperの環境構築と使い方
- Whisper文字起こしの活用法
- Whisper APIとは
- Whisperを使用する際の注意点

会議の議事録作成やインタビューの文字起こしに多くの時間を費やしていませんか?OpenAIが開発した音声認識AI「Whisper」は、そんな手間のかかる文字起こし作業を大幅に効率化できる無料のツールとして注目を集めています。特に日本語の文字起こしでは5.3%という低い誤認識率を実現し、実用的な精度で作業を自動化できます。本記事では、Whisperの基本的な特徴から、環境構築の手順、実践的な活用方法まで、分かりやすく解説します。無料で使えて高精度なWhisperを、ぜひビジネスの現場で活用してみましょう。

目次
Whisperとは|OpenAIが提供する文字起こしAI
引用:https://openai.com/index/whisper/
音声認識技術の革新的な進歩により、文字起こし作業は大きく効率化されています。その中でも特に注目を集めているのが、OpenAIが開発した音声認識AI「Whisper」です。無料で利用でき、多言語に対応した高精度な文字起こしを実現する本ツールについて、その特徴と性能を詳しく見ていきましょう。
OpenAIが開発した無料の音声認識AI
Whisperは、ChatGPTで知られるOpenAIが開発・公開している無料の音声認識モデルです。このツールは、入力された音声データを高精度でテキストに変換する文字起こし機能を提供しています。特筆すべきは、このような高性能なAIモデルが無料で公開されていることで、これにより多くの開発者や企業が高品質な音声認識機能を自社のサービスに組み込むことが可能になりました。
Whisperの主な特徴
・ 完全無料で利用可能な音声認識エンジン
・ オープンソースで提供され、カスタマイズが可能
・ 多言語対応による柔軟な音声認識
・ ローカル環境での実行が可能
68万時間の学習データで実現した高精度
Whisperの高い精度の背景には、Webから収集された68万時間もの多言語音声データを用いた大規模な学習が存在します。この膨大なデータセットを活用した教師あり学習により、Whisperは様々な言語や音声環境に対応できる強固な認識能力を獲得しています。特に、学習データに含まれる多様な音声パターンにより、アクセントの違いやバックグラウンドノイズがある状況でも安定した文字起こしが可能になっています。
日本語の文字起こし精度が高い
Whisperの特筆すべき特徴の一つが、日本語の文字起こしにおける高い精度です。Fleursデータセットにおける言語別の単語誤り率(WER)で、日本語は4.9%という優れた結果を示しており、これはスペイン語、イタリア語、韓国語、ポルトガル語、英語、ドイツ語、ポーランド語、カタロニア語に次ぐ高精度な認識率です。この高い日本語対応能力により、ビジネス会議の議事録作成や、インタビューの文字起こしなど、幅広い実務での活用が期待されています。
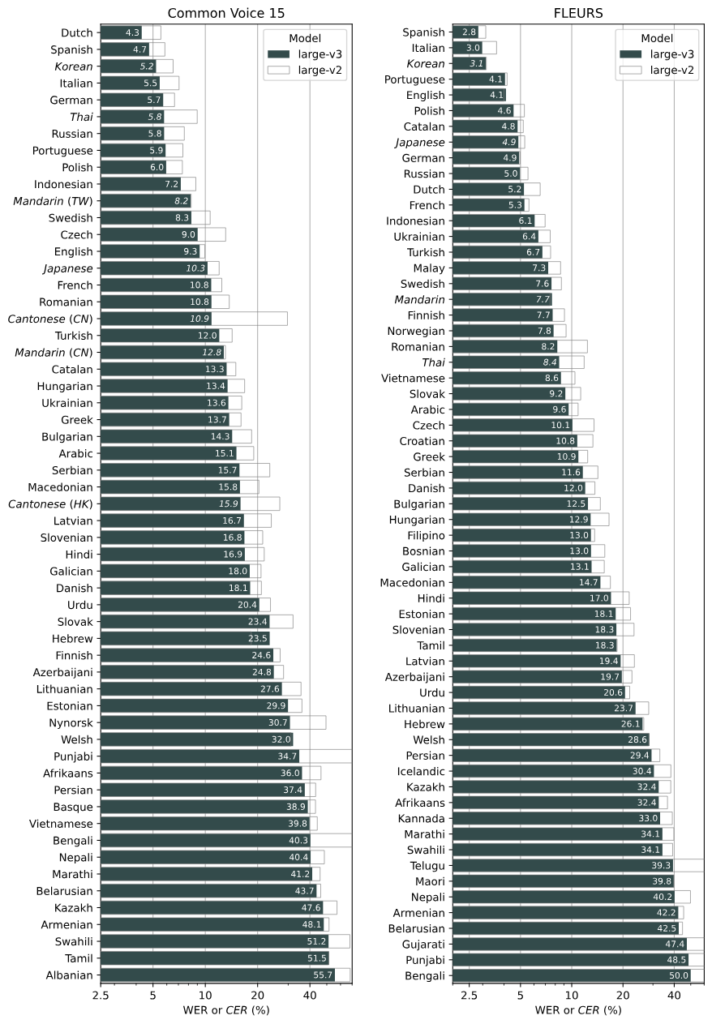
引用:https://github.com/openai/whisper
Whisperの5つのモデルサイズを解説

※引用:https://github.com/openai/whisper
Whisperには、用途や必要な精度に応じて選択できる5つの異なるモデルサイズが用意されています。各モデルサイズは処理速度、精度にトレードオフがあり、使用環境や目的に合わせて最適なものを選択することが重要です。ここでは、各モデルサイズの特徴と実際の使用シーンについて詳しく解説していきます。
tinyモデル
tinyモデルは、Whisperの中で最も軽量なモデルです。わずか39Mのパラメータ数で、基本的な音声認識タスクを高速に処理することができます。主に短い音声データの文字起こしや、リアルタイムでの処理が必要な場合に適しています。ただし、固有名詞や専門用語の認識精度は他のモデルと比べて低く、漢字とカタカナの使い分けなどで誤りが発生しやすい特徴があります。
baseモデル
baseモデルは、74Mのパラメータを持ち、tinyモデルよりも高い認識精度を実現します。一般的な会話や基本的なビジネス文書の文字起こしに適しており、特に日本語の一般的な表現や基本的な用語の認識において安定した性能を発揮します。処理速度とリソース消費のバランスが取れており、多くのユースケースで実用的な選択肢となっています。
smallモデル
smallモデルは、244Mのパラメータを持ち、より複雑な音声認識タスクに対応できます。特に、句読点の配置や文章の区切りの認識において優れた性能を示します。ビジネス会議や講演の文字起こしなど、より正確な文章構造が求められる場面での使用に適しています。baseモデルと比較して、特に長文での認識精度が向上しています。
mediumモデル
mediumモデルは、769Mのパラメータを持ち、高度な音声認識能力を提供します。特に専門用語や固有名詞の認識精度が向上し、より複雑な文脈理解が必要なケースでも優れた性能を発揮します。学術的な講演や専門的な会議の文字起こしなど、高い精度が要求される場面での使用に適していますが、それに伴いGPUメモリの要求も大きくなります。
largeモデル
largeモデルは、1550Mという最大のパラメータ数を持ち、Whisperの中で最も高い認識精度を実現します。特に日本語においては、カタカナ語や専門用語、固有名詞などの認識で他のモデルを大きく上回る性能を示します。また、ノイズの多い環境下での音声認識や、複数の話者が存在する音声データの処理においても優れた結果を残します。ただし、処理に必要なリソースも最も大きく、高性能なGPUが必要となります。
Whisperの環境構築と使い方

Whisperを実際に使用するには、適切な環境構築が必要です。ここでは、最も手軽に利用できるGoogle Colaboratory(Colab)を使用した環境構築から、基本的な文字起こしの手順、そして精度を向上させるためのコツまでを詳しく解説します。初めての方でも安心して始められるよう、ステップバイステップで説明していきます。
Google Colabでの簡単セットアップ
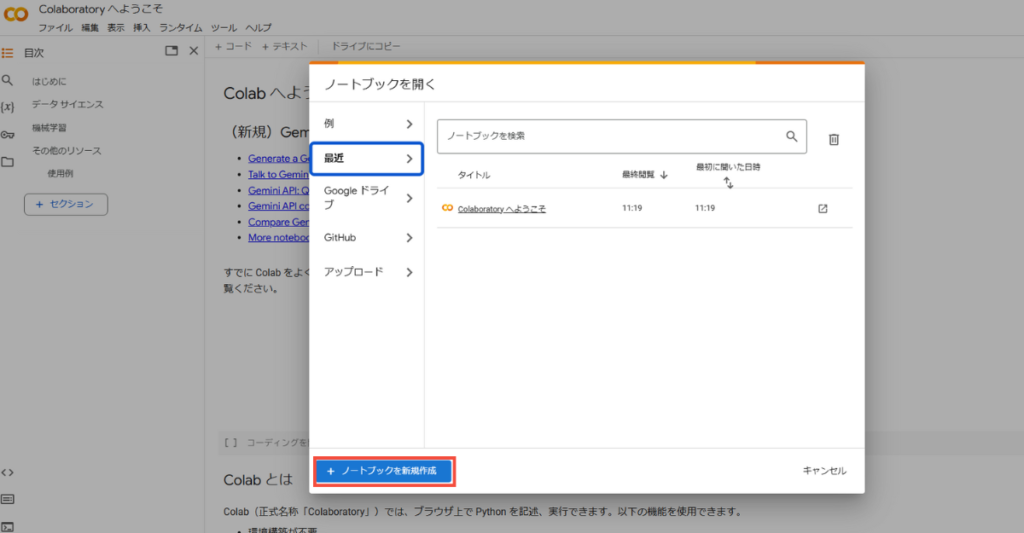
Google Colaboratory(Colab)での環境構築は、以下の手順で簡単に行えます。
まず、サイトにアクセスして、Googleアカウントでログインし、新しいノートブックを作成します。
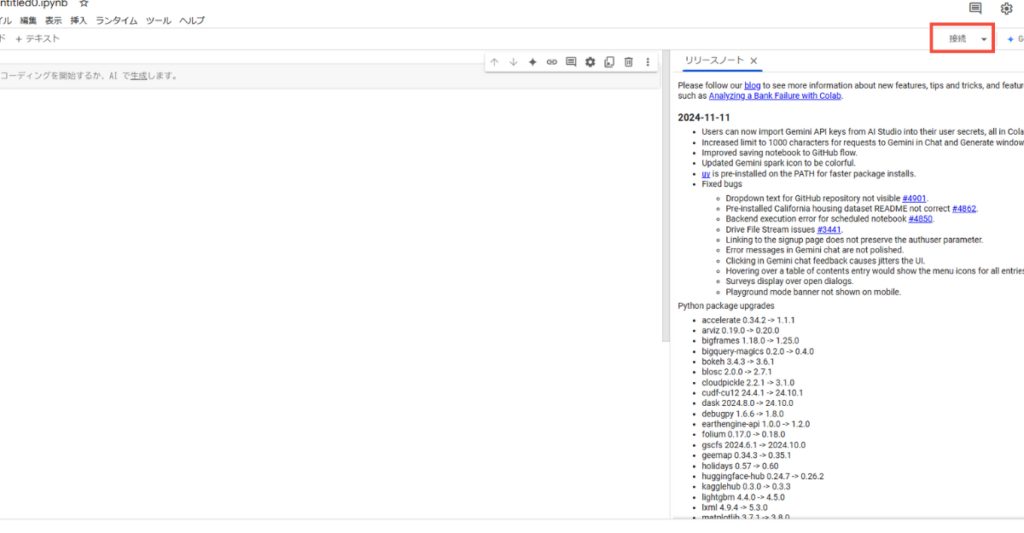
次に、画面右上の「接続」をクリックします。
続いて「リソース」をクリックして、画面下部の「ランタイムのタイプを変更」を押します。
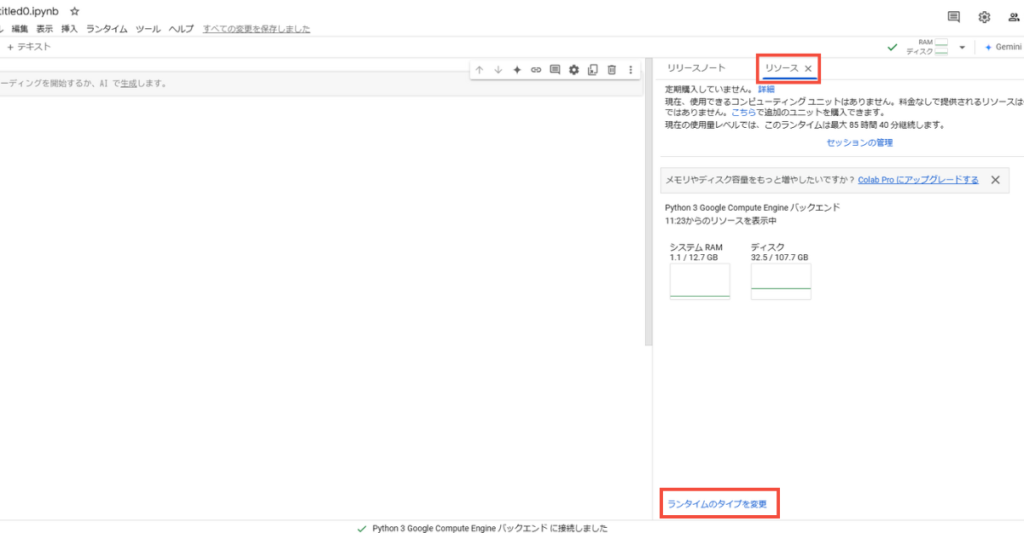
ランタイムのタイプを「T4 GPU」に変更します。これにより、高速な処理が可能になります。
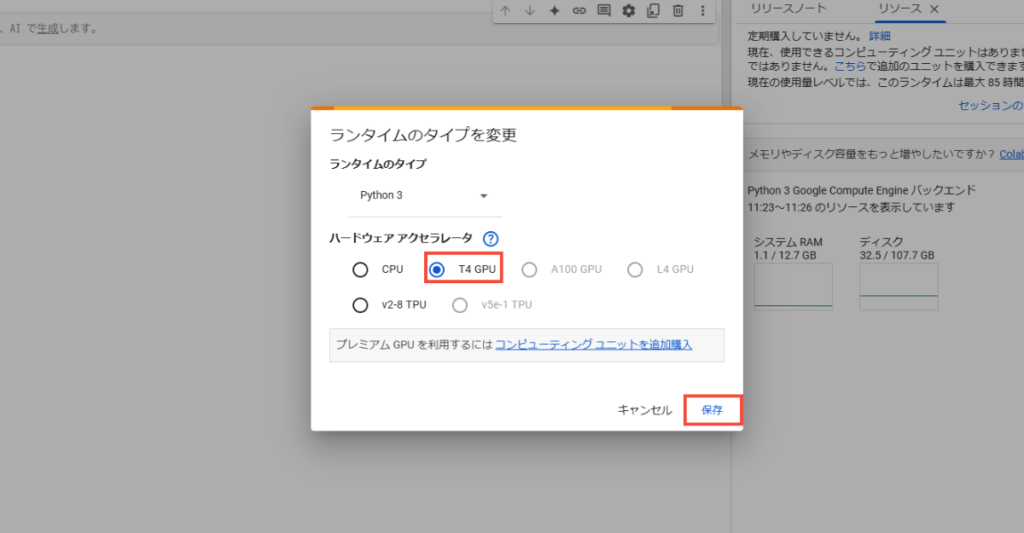
その後、Whisperをインストールするために、以下のコマンドを下記の赤枠内に入力して、三角の実行ボタンを押します。
!pip install git+https://github.com/openai/whisper.git
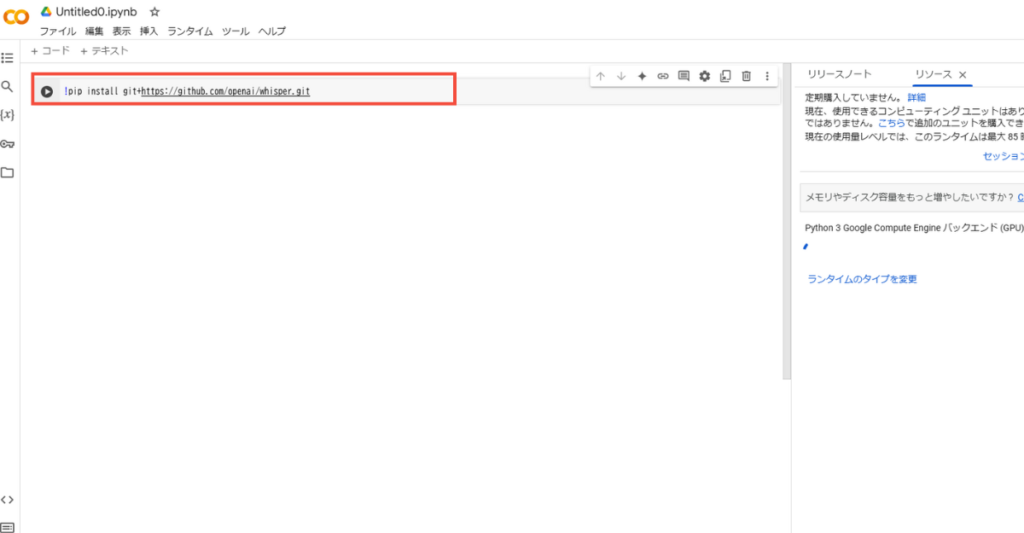
続いて、「+コード」を選択して、以下のコマンドを下記の赤枠内に入力して、三角の実行ボタンを押します。
import whisper
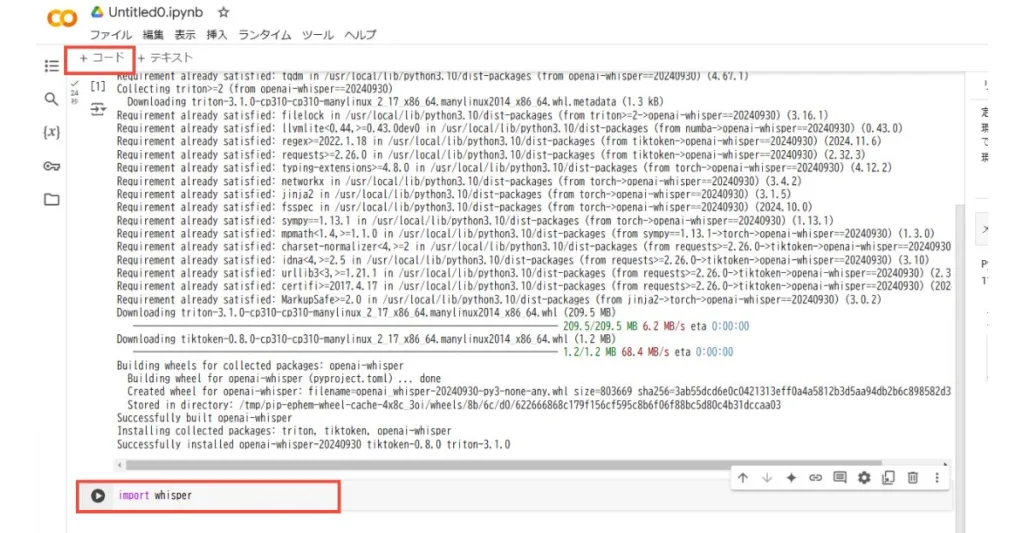
これで、基本的な環境構築は完了です。
基本的な文字起こしの手順
環境構築が完了したら、実際の文字起こし作業に移ります。まず、処理したい音声ファイルをGoogle Colabのcontentフォルダにアップロードします。
左側メニューの「content」の赤枠メニューを押して、書き起こししたい音声ファイルをアップロードします。
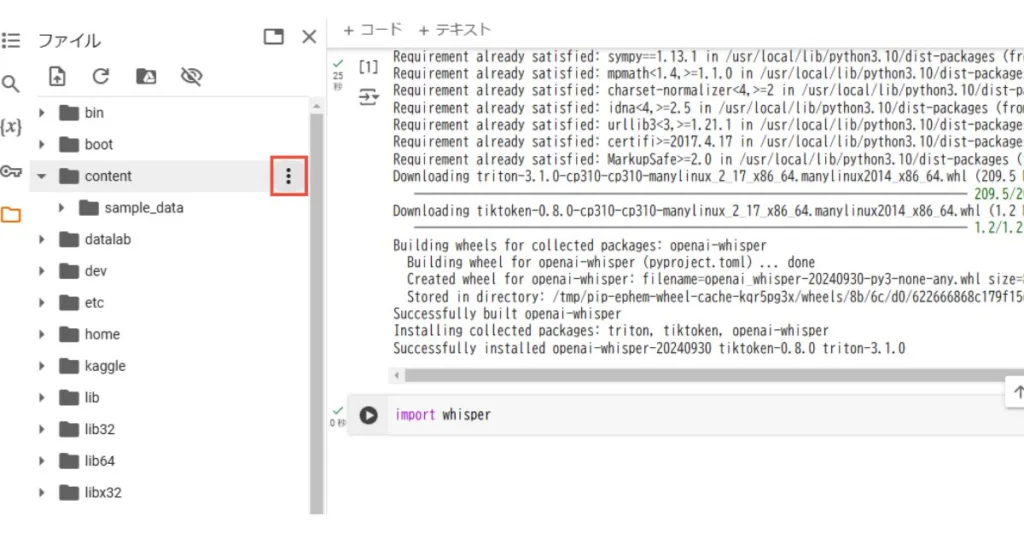
今回は「dify立ち上げ.mp3」というファイルをアップロードしました。「content」のファイル配下に反映されたら、アップロード成功です。サポートされている音声形式は、mp3、mp4、mpeg、mpga、m4a、wav、webmです。
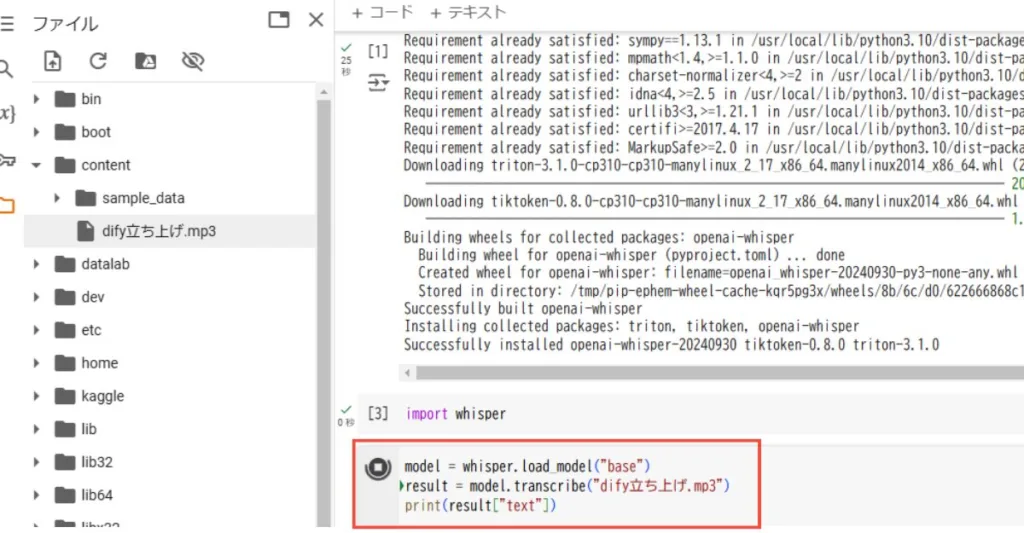
続いて、文字起こしのコードを入力して実行します。基本のコードは以下の通りです。このコードでは、「base」モデルを使用していますが、必要に応じて「tiny」から「large」まで変更可能です。
“`python
model = whisper.load_model(“base”)
result = model.transcribe(“音声ファイル名”)
print(result[“text”])
“`
コードを入力して実行ボタンを押します。
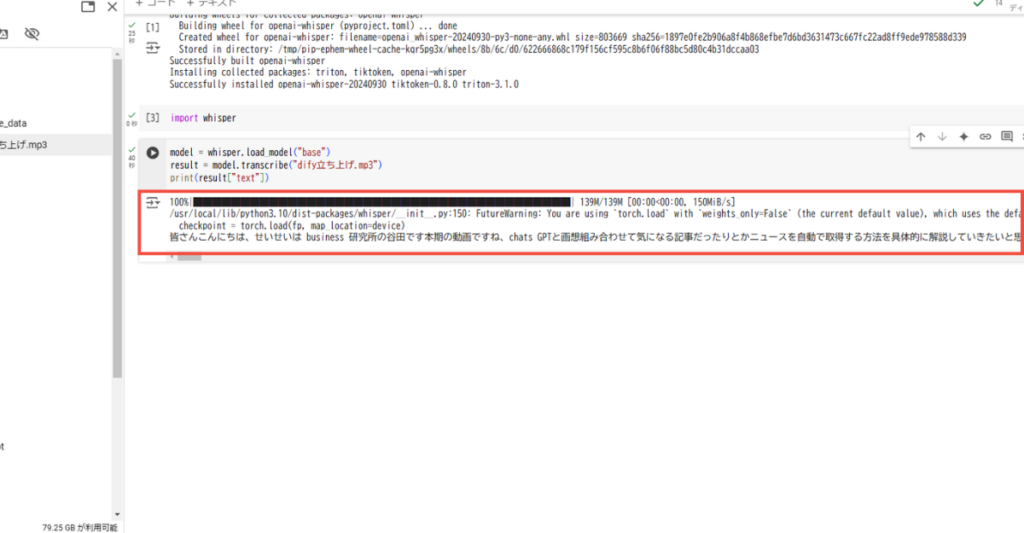
下記の通り、音声ファイルをもとに書き起こしが出力されます。
実行時のおすすめ設定とコツ
Whisperの性能を最大限に引き出すためには、いくつかの重要な設定とコツがあります。まず、処理する音声の言語を指定することで、認識精度が向上します。例えば、日本語の音声を処理する場合は、以下のように言語を指定します。
“`python
result = model.transcribe(“音声ファイル名”, language=”ja”)
“`
また、生活騒音がある環境での録音データを処理する場合は、largeモデルを使用することで、より高い精度が期待できます。実際の調査では、55dB-A程度の生活騒音下でも、特に固有名詞以外の部分では高い精度を維持できることが確認されています。
さらに、長時間の音声を処理する場合は、メモリ使用量に注意が必要です。Google Colabの無料版では利用可能なメモリに制限があるため、必要に応じて音声ファイルを分割して処理することをお勧めします。また、処理結果を保存する際は、以下のようにテキストファイルとして出力することで、後での編集が容易になります。
“`python
with open(“output.txt”, “w”, encoding=”utf-8″) as f:
f.write(result[“text”])
“`
実践で活躍!Whisper文字起こしの活用法

Whisperの高い文字起こし精度は、様々なビジネスシーンで活用できる可能性を秘めています。ここでは、実際のビジネス現場での活用方法から、より良い結果を得るためのテクニック、そして品質を向上させるためのコツまでを、実践的な視点から解説していきます。
ビジネス文書作成での活用ポイント
ビジネス文書作成におけるWhisperの活用は、特に議事録やレポート作成の効率を大きく向上させます。例えば、商談や企画会議の録音データから文字起こしを行う場合、まず音声を5-10分程度のセグメントに分割することで、処理の負荷を軽減し、より正確な文字起こしが可能になります。また、重要なキーワードや専門用語が含まれる場合は、largeモデルを使用することで、より高い認識精度を確保できます。さらに、文字起こし後のテキストを段落ごとに整理し、見出しや箇条書きを追加することで、読みやすい文書に仕上げることができます。
インタビュー・会議録作成のテクニック
インタビューや会議の録音データを文字起こしする際は、音声の品質が結果を大きく左右します。まず、録音時には話者から50cm程度の距離を確保し、できるだけ静かな環境で録音することが重要です。複数の話者がいる場合は、それぞれの発言が明確に区別できるよう、適切な間隔を空けて着席することをお勧めします。また、文字起こしの精度を上げるためには、発言者に「ゆっくり、はっきりと」話すことを依頼し、重要なポイントでは特に明瞭な発声を心がけてもらうことが効果的です。さらに、専門用語や固有名詞が多用される場合は、事前にリストを作成し、発言時には特に丁寧な発音を心がけることで、認識精度を向上させることができます。
ノイズ環境下での精度を上げるコツ
実際のビジネス環境では、完全な無音状態での録音は難しいものです。しかし、Whisperは適切な設定と工夫により、ある程度のノイズ環境下でも高い精度を維持できます。例えば、55dB-A程度の一般的なオフィス環境でも、largeモデルを使用することで、固有名詞以外の文章については高い認識精度を実現できることが実証されています。
ノイズ対策としては、指向性マイクの使用や、録音デバイスのノイズキャンセリング機能の活用が効果的です。また、エアコンや換気扇などの定常的なノイズについては、録音前に音源から離れた場所を選ぶことで、影響を最小限に抑えることができます。会議室での録音時は、窓を閉め、エアコンの風が直接当たらない位置にマイクを設置するなど、細かな配慮が精度向上につながります。
Whisper APIとは?

2023年3月にOpenAIから公開されたWhisper APIは、高性能な音声認識モデルを手軽に利用できるサービスとして注目を集めています。オープンソース版のWhisperとは異なり、APIを介して簡単に音声認識機能を実装できる特徴があり、開発者や企業にとって新たな可能性を開きました。
APIの概要
Whisper APIは、HTTPリクエストを通じて音声認識機能を提供するWebサービスです。対応している音声フォーマットは、mp3、mp4、mpeg、mpga、m4a、wav、webmと幅広く、最大ファイルサイズは25MBまでとなっています。APIは音声ファイルをアップロードすると、テキストデータとして文字起こし結果を返却する仕組みになっており、必要に応じて言語指定や翻訳機能の利用も可能です。また、ChatGPT APIと組み合わせることで、文字起こしした内容の要約や分析など、より高度な処理も実現できます。
料金と機能
料金体系はシンプルで、音声データ1分あたり0.006ドル(約0.92円)という低コストでの利用が可能です。ファイルサイズは最大25MBまで対応しており、それ以上の場合は分割してアップロードする必要があります。基本的な機能として以下を提供しています。
・音声データの翻訳機能
・音声からテキストへの変換(文字起こし)
・複数言語への対応
・意味をなさない発言の自動除去機能
参考:OpenAIの料金ページ
APIの活用メリット
Whisper APIの活用により、手動での文字起こし作業が不要となり、業務効率を大幅に向上できます。他の音声認識サービスと比較しても高い認識精度を低コストで実現しており、コストパフォーマンスに優れています。
また、議事録作成、言語学習アプリケーション、カスタマーサポートなど、様々な用途での活用が可能で、リアルタイムでの音声認識により素早いテキスト化を実現できることから、企業や個人を問わず幅広く活用されています。
Whisperを使用する際の注意点2つ

Whisperは強力な文字起こしツールですが、実際の運用にあたっては考慮すべき重要な注意点があります。ここでは、特に気をつけるべき2つの重要なポイントについて詳しく解説し、安全かつ効果的な活用方法を提案します。
機密情報が含まれるデータは学習させない
Whisperを使用する際の最も重要な注意点は、機密情報の取り扱いです。特にオープンソース版のWhisperを使用する場合、処理される音声データの安全性について十分な注意が必要です。企業の機密情報、個人情報、医療情報などのセンシティブな情報が含まれる音声データの処理は、原則として避けるべきです。
これは、音声データがローカル環境で処理される場合でも同様です。もし機密性の高い情報を含む音声の文字起こしが必要な場合は、適切なセキュリティ対策が施された専用の文字起こしサービスの利用を検討するべきです。また、Whisper APIを使用する場合も、OpenAIのプライバシーポリシーと利用規約を十分に確認し、データの取り扱いについて組織内で明確なガイドラインを設定することが重要です。
環境構築やプログラミング知識が必要
もう一つの重要な注意点は、Whisperの利用に必要な技術要件です。特にオープンソース版を使用する場合、Python環境の構築やコマンドライン操作の基本的な知識が必要となります。また、GPUを使用した処理を行う場合は、CUDA環境の構築や、適切なドライバーのインストールなども必要になります。これらの技術要件は、特に技術部門以外のユーザーにとっては大きな障壁となる可能性があります。
そのため、組織内での運用を検討する場合は、以下の点について事前に検討することが推奨されます:担当者のスキルレベルの確認、必要なトレーニングの実施、技術サポート体制の整備、そして必要に応じて外部の専門家への相談です。また、技術的なハードルを避けたい場合は、Whisper APIや、Whisperを活用した既存のサービスの利用を検討することで、より手軽に文字起こし機能を活用することが可能です。
まとめ:Whisperで文字起こしを行い、業務を効率化しよう

OpenAIが開発したWhisperは、無料で利用できる高性能な文字起こしAIとして、ビジネスシーンでの活用が期待されています。特に日本語の文字起こしにおいては5.3%という低い単語誤り率を実現しており、実用的な精度で文字起こしが可能です。
Whisperの活用を検討している方は、まずGoogle Colaboratoryでの試用から始めることをお勧めします。実際の業務での使用シーンを想定しながら、必要な精度と処理速度のバランスを見極め、適切なモデルを選択することで、効率的な文字起こしワークフローを構築することができます。組織での本格的な導入を検討する場合は、技術要件やセキュリティ面での対策を十分に検討した上で、OpenAIが提供するWhisper APIの活用も視野に入れることで、より安定的な運用が可能になるでしょう。

【生成AI活用でお困りではないですか?】
株式会社アドカルは主に生成AIを活用したマーケティングDXや業務効率化に強みを持った企業です。
貴社のパートナーとして、少数精鋭で担当させていただくので、
「生成AIをマーケティング業務に活用したい」
「業務効率を改善したい」
「自社の業務に生成AIを取り入れたい」
とお悩みの方は、ぜひ弊社にご相談ください。
貴社のご相談内容に合わせて、最適なご提案をさせていただきます。
サービスの詳細は下記からご確認ください。無料相談も可能です。


